D-Lib Magazine
January/February 2017
Volume 23, Number 1/2
Table of Contents
Graph Connections Made By RD-Switchboard Using NCI's Metadata
Jingbo Wang
National Computational Infrastructure, Australia
http://orcid.org/0000-0002-3594-1893
jingbo.wang@anu.edu.au
Amir Aryani
Australian National Data Service, Melbourne, Australia
http://orcid.org/0000-0002-4259-9774
amir.aryani@ands.org.au
Ben Evans
National Computational Infrastructure, Australia
ben.evans@anu.edu.au
Melanie Barlow
Australian National Data Service, Melbourne, Australia
http://orcid.org/0000-0002-3956-5784
melanie.barlow@ands.org.au
Lesley Wyborn
National Computational Infrastructure, Australia
http://orcid.org/0000-0001-5976-4943
lesley.wyborn@anu.edu.au
Corresponding Author: Amir Aryani, amir.aryani@ands.org.au
https://doi.org/10.1045/january2017-aryani
Abstract
This paper demonstrates the connectivity graphs made by Research Data Switchboard (RD-Switchboard) using NCI's metadata database. Making research data connected, discoverable and reusable are some of the key enablers of the new data revolution in research. We show how the Research Data Switchboard identified the missing critical information in our database, and what improvements have been made by this system. The connections made by the RD-Switchboard demonstrated the various use of the datasets, and the network of researchers and cross-referenced publications.
Keywords: Data Collection, Data Discovery, Graph Database
1 Introduction
The National Computational Infrastructure (NCI) at the Australian National University (ANU) hosts over 10 PB of national and international research data that has strong community interest and high national significance [1]. As a component of this, the approach to the management of Data Collections has become an essential activity at the NCI in Australia [2]. Of interest to both users and funding agencies is the usages of those national data collections. One way of reporting usage is to count how many publications cite the data collections hosted at NCI; however, that is not practical due to the long life cycle of research and publication. Björk and Solomon [3] reports an average 9-18 month delay from submission to publication in different domains. Even with the recent improved review and publishing processes, it still takes weeks to several months until publications are accessible to researchers. In some domains, the practice of data citation has not been properly established to support tracking the connections between papers and datasets using standard citation schema. In addition, the datasets might not be accessible, which makes it hard to cite the dataset in the publication's references.
Research Data Switchboard (RD-Switchboard) is an open and collaborative software solution initiated by the Data Description Registry Interoperability (DDRI) Working Group of the Research Data Alliance (RDA) [4]. This working group has participants from Australian National Data Service, Dryad, CERN and a number of international partners. RD-Switchboard connects datasets together on the basis of co-authorship or other collaboration models such as joint funding and grants. The best metaphor for this system is the SEE ALSO section in online bookstores, where customers are invited to look at other products by the same author, related topics or similar publishers [5].
The introduction of RD-Switchboard to NCI's national data collection metadata database brings a breath of fresh air to the challenge of linking publications to datasets, and provides a new approach to address the shortage of formal data citation in publications. RD-Switchboard connects researchers, organisation, datasets and papers, and these new connections provide the capability to link datasets and publications via researchers and organizations. In RD-Switchboard, datasets are connected to a number of researchers and organizations through different relationship types, such as IsOwnerOf, IsCustodianOf, etc; the publication is also connected to researchers and organizations via registries such as ORCID, or university profile pages. The critical component is the usage of international identifiers and open linked data enablers that connects different parties (entities) such as funding agencies, researchers and research institutions.
This paper will demonstrate the technical implementation of RD-Switchboard at NCI; the connections made by RD-Switchboard using NCI's metadata database; the improvement that we made to our metadata database based on the observation of the initial connections; and the connections made between datasets and publication through researchers/organisations.
2 RD-Switchboard Implementation
NCI RD-Switchboard is hosted on a VM within NCI's cloud infrastructure. This system uses the Neo4j graph database that supports the RD-Switchboard inference components. The Neo4j browser provides a query interface to readily identify connections among the metadata records. The RD-Switchboard harvester collects XML files of all metadata records and stores them in its internal repository. Later, these XML files will be imported into its Neo4j graph database, which is ultimately used by the RD-Switchboard inference engine. NCI maintains this XML harvest and import process using an automated tool, which triggers the harvest and import process for any updated metadata information. Due to the nature of consistent updates on NCI's metadata, the RD-Switchboard is implemented to harvest metadata on a regular basis to synchronise changes. A series of database snapshots are backed up to enable tracking the changes of the graph database in chronological order. The Neo4j browser then provides a query interface to identify connections within the graph database. NCI has implemented some fail-safe procedures around this ingest process to protect the information in operations.
NCI manages the harvesting and import processes using an automation tool. The tool triggers the harvest process and imports any new records or updates existing records. RD-Switchboard enables scalable harvesting when multiple databases are imported. NCI data backup process operates in three layers. (see Figure 1).
- The program automatically harvests from a set of metadata catalogues and stores the harvested data into a repository on a weekly basis.
- To prevent intermittent data importing, the Neo4j server can be paused during the import process. The behaviour of Neo4j server is recorded in the process log file with timestamps.
- Once the import process is complete, the Neo4j server is restarted. The graph database is archived to a separate repository for backup and recovery purposes.
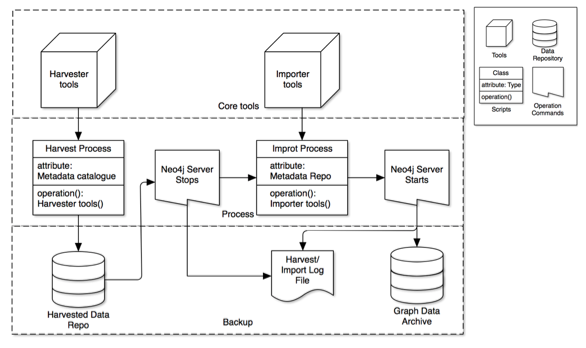
Figure 1: Automatic data harvest/import process flowchart.
3 Data Cleaning
In the absence of organisation ID, NCI catalogues using the organisation name as the organisation main identifier. We find that listing all the organisation names helps to clean up the errors in the metadata. When organisations are printed on the same page, it is easy to see variations of organisation names when listed side by side. Figure 2 gives a few examples of erroneous/inconsistent organisation names using this approach. The inconsistency of the names causes the subsequent problem of disconnected nodes. The highlighted yellow item is a mistake resulting from entering a role into the wrong field. In practice, those errors are difficult to discover using a manual process. RD-Switchboard lists the organisations with their connected nodes (including publications and datasets). Such a list enables identifying problems resulting from similar names having been linked to related nodes.
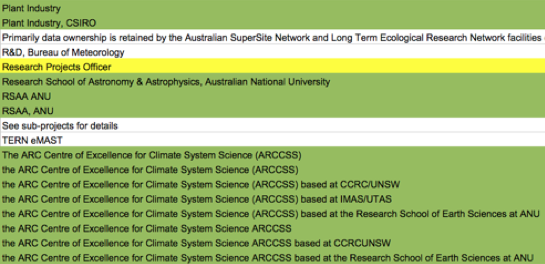
Figure 2: Example of faulty, inconsistent organization name, wrong field value identified by the RD-Switchboard.
4 Datasets jointly managed by multiple agencies
Another feature of data ownership and custodianship is having multiple researchers/organisations related to one collection. This situation is commonly found in large internationally collaborated projects, such as the climate model (e.g. CMIP5) or satellite imagery data collections (e.g. MODIS). Associated organisations are listed as having different roles in NCI's data management plan. A clear and centralised overview (Figure 3) shows how each organisation is associated with the dataset. Additionally, if data is being processed at NCI with derived data products further published by NCI's users, a sketch of linked dots makes this situation understandable at a glance. The connection between the source and derived data can also be clearly described using RD-Switchboard through the connection with researchers who generated the derived data products.
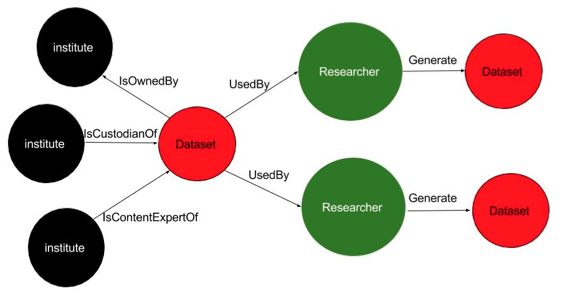
Figure 3: A centralised overview of a dataset related to various partner organisations with specific roles, and the relationship with its derived product.
5 Connections Identified in the Graph Database
The key elements to make connections are identifiers in RD-Switchboard. Identifiers are widely available within the research community. For example, researchers have personal identifiers such as ORCID, Scopus ID, and so on. Organisations have a website URL, and some of them have institute identifiers. Papers have DOIs, and books have an ISBN. Finally, funding comes usually with a grant ID. RD-Switchboard utilises those identifiers to make connections within the graph database. Figure 4 demonstrates the merging process among entities who have the same identifiers. Therefore, it is critical to make identifiers available so that entities can be associated with each other, so as to build the connections.
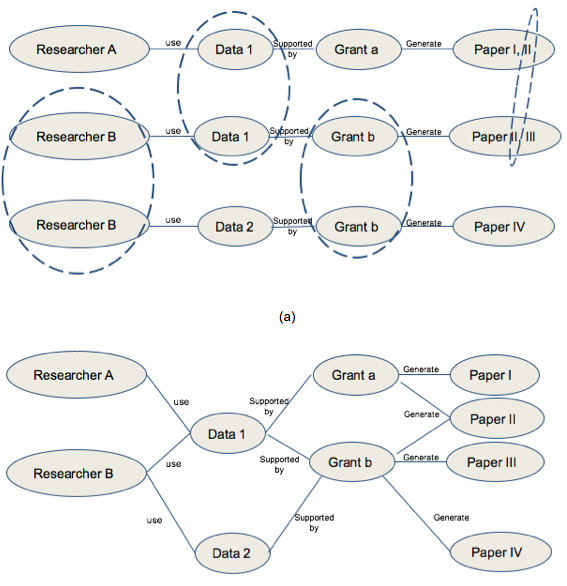
Figure 4: (a) Each individual catalogue record describes a linear relationship among entities. Entities with the same identifier are circled.
(b) Circled entities are converged into a single node, which is presented in graph database using RD-Switchboard.
Figure 5 demonstrates connections when NCI's collection level metadata is imported. RD-Switchboard builds the connection among researchers, datasets, organisations and publications using existing metadata database. It is critical to have identifiers to make connections.
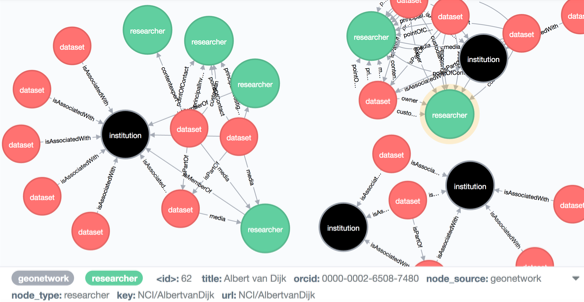
Figure 5: Connection screenshot of initial metadata database. The ORCID of the researcher is shown at the bottom when the browser stopped on that node.
6 Connections of Interest to Researchers
The universal unique identifier also provides opportunity when NCI's RD-Switchboard is connected with external databases, such as Figshare and CERN. The NCI nodes will automatically link with the external nodes with the same identifier. The result makes the associated nodes connected across platforms. The external connections are particularly useful for researchers who want to make connections to non-NCI nodes in the future. Therefore, universally recognised identifiers, such as DOI and ORCID, are highly recommended to be registered for this purpose.
The connections made available through RD-Switchboard provided a centralised view which can answer some questions straight away, questions which are difficult to answer by just searching the metadata records. Table 1 lists a few questions that can be answered by RD-Switchboard through graph queries.
Table 1: Generated questions that can be answered by graph database query.
| What is the usage of NCI's datasets? |
How many datasets published at NCI are being referenced in research journal articles? |
| What is the level of awareness of the available datasets within the research community? |
How many researchers/institutes are connected to the datasets? |
If I would like to know more about this dataset, who should I contact?
What previous research was done using this dataset?
|
How do I find connections between NCI datasets and international repositories such as CERN and ORCID — data discovery? |
RD-Switchboard also acts as a machine actionable information hub. Figure 6 illustrates our experiences with a set of datasets that are of interest to a number of different groups. The data life cycle footprint and its connections to researchers are clearly shown by the graphic view of RD-Switchboard. The transparency and centralised view encourages possible collaborations among groups who have similar research interests. On the other hand, it avoids duplicated efforts in the case of a conflict of interest. Before introducing the RD-Switchboard, the data managers have to talk to each group to clarify things. Sometimes, communication may be missed due to unawareness and unavailability of researchers. However, the availability of the centralised view at RD-Switchboard enhances a data manager's efforts to communicate with the various research groups who access NCI's data repository.
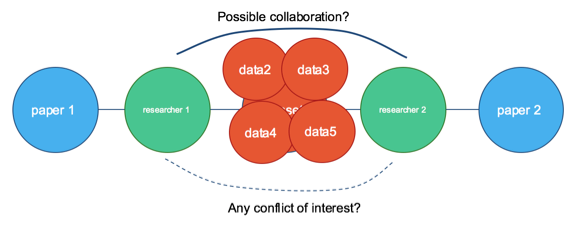
Figure 6: RD-Switchboard, acting as a centralised information hub, brings data lifecycle footprint transparency to users.
7 Summary
In this paper, we demonstrated the application of Research Data Switchboard at NCI, and we have discussed how this software solution helped to improve the connectivity of the NCI research data collections. The new connections introduced by Research Data Switchboard fills the gap between research datasets and publications, and we hope these connections eventually result in researchers conducting better literature reviews. In addition, it will save significant amounts of time when data managers and research administrators conduct a statistical analysis for usage of research data.
The new connections improve the visibility of the NCI datasets and provide new ways for discovery services such as Research Data Australia to promote the reuse of the NCI datasets with information such as related publications, ORCID researchers and grants. We think Research Data Switchboard is a handy and useful tool which can provide a significant support for making data discoverable and reusable.
Acknowledgements
The NCI High Performance Data Node is supported by the Australian Government NCRIS funded Research Data Storage Infrastructure (RDSI) and Research Data Services (RDS) projects and the RDA Data Description Registry Interoperability (DDRI) Working group.
References
| [1] |
Evans, B. J. K., Wyborn, L., Lewis, A., Foster, F., Minchin, S., Pugh, T., Uhlherr, A., Evans, B. J. (2014) Computational Environments and Analysis methods available on the NCI HPC & HPD Platform. American Geophysical Union Fall meeting, San Francisco, USA, December 13-17, 2014. |
| [2] |
Wang, J., Evans, B., Bastrakova, I., Ryder, G., Martin, J., Duursma, D., Gohar, K., Mackey, T., Paget, M., Siddeswara, G. and Wyborn, L. (2014) Large-Scale Data Collection Metadata Management at the National Computation Infrastructure. American Geophysical Union Fall meeting, San Francisco, USA, December 13-17, 2014. |
| [3] |
Bo-Christer, B., Solomon, D. (2013). The publishing delay in scholarly peer-reviewed journals. |
| [4] |
Aryani, A. (2016) Data Description Registry Interoperability WG: Interlinking Method and Specification of Cross-Platform Discovery. Research Data Alliance. https://doi.org/10.15497/RDA00003 |
| [5] |
Aryani, A., Burton, A., Treloar, A. (2015) Research Data Switchboard: Finding Connections to Your Data. eResearch Australasia 2015. https://doi.org/10.6084/m9.figshare.4212261.v1
|
About the Authors
Jingbo Wang is the Data Collections Manager at the National Computational Infrastructure where she is leading the migration of data collections onto the RDS (Research Data Service) funded filesystems. Dr. Wang's focus is on building the infrastructure to support data management, data citation, data ingest publishing logistics and provenance capture system. She is also interested in how to provide the best data services to the research community through provenance, graph database, etc., technology. As a geophysicist, she is also working and how to advance the science through interdisciplinary research that combines the HPC/HPD platform with the massive geophysical data collection at NCI.
Amir Aryani is working in the capacity of a project manager for Australian National Data Service (ANDS), and he is the co-chair of the Data Description Registry Interoperability WG in Research Data Alliance. Dr. Aryani has a PhD in computer science. His research is focused on the interoperability between research information systems, and he is leading the Research Graph project to build a large-scale distributed graph that enables connecting heterogeneous data infrastructures.
Ben Evans is the Associate Director of Research, Engagement and Initiatives at the National Computational Infrastructure. Dr. Evans oversees NCI's programs in highly-scalable computing, Data-intensive computing, data management and services, virtual laboratory innovation, and visualization. He has played leading roles in national virtual laboratories such as the Climate and Weather Science Laboratory (CWSLab) and VGL, as well as major international collaborations, such as the Unified Model infrastructure underpinning the ACCESS system for Climate and Weather, Earth Systems Grid Federation (ESGF), EarthCube, the Coupled Model Inter-comparison Project (CMIP), and its support for the Intergovernmental Panel on Climate Change (IPCC).
Melanie Barlow has a Bachelor degree in Computer and Information Science. She works as a Technical Analyst for the Australian National Data Service, helping people make research data findable for reuse with attribution. Her professional career includes software development, system architecture as well as business and technical analysis.
Lesley Wyborn joined the then BMR in 1972 and for the next 42 years held a variety of science and geoinformatics positions as BMR changed to AGSO then Geoscience Australia. In 2014, Dr. Wyborn joined the ANU and currently has a joint adjunct fellowship with NCI and the Research School of Earth Sciences. She has been involved in many Australian eResearch projects, including the NeCTAR funded Virtual Geophysics Laboratory, the Virtual Hazards, Impacts and Risk Laboratory, and the Provenance Connectivity Projects. She is Deputy Chair of the Australian Academy of Science 'Data for Science Committee'. In 2014 she was awarded the Australian Public Service Medal for her contributions to Geoscience and Geoinformatics, and in 2015, the Geological Society of America, Geoinformatics Division 2015 Outstanding Career Achievement Award.