|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2016
Volume 22, Number 11/12
A Doomsday Scenario: Exporting CONTENTdm Records to XTF
Andrew Bullen
Illinois State Library
abullen@ilsos.net
DOI: 10.1045/november2016-bullen
Abstract
Due to the challenging state budget situation in Illinois, Andrew Bullen of the Illinois State Library was asked to explore how the existing CONTENTdm collections could be migrated to another platform should the State Library be unable to pay its bill for its existing services. Andrew chose XTF, a resource at hand and a logical candidate for undertaking the transfer, and methods that were already available that would allow rapid migration. He describes in detail the process of transferring three collections that represented a reasonable cross section of Illinois Digital Archives content from CONTENTdm to XTF, and offers an evaluation of his test migration approach and lessons learned.
1 Introduction
Residents of Illinois and Illinois state government employees are living in interesting budgetary times. As of this writing, the Governor and the Illinois State Legislature have yet to pass a budget for FY2016. There is a stopgap budget passed for part of FY2017; however, the budget only covers some expenses until the November 2016 elections. What happens after that is unknown. Naturally, we are concerned about being able to support existing services to Illinois libraries.
One of the main services that we provide to Illinois libraries is the Illinois Digital Archives (IDA), a repository for the digital collections of libraries and cultural institutions in the State of Illinois, based on CONTENTdm. In light of budget concerns, we thought it prudent to explore what would happen to the collections on IDA if we could not pay our subscription fee to OCLC and were forced to cancel the service. There are currently 156 disparate collections in IDA and more than 468,000 objects in these collections, a fairly substantial instance of CONTENTdm. How could we replace it if we had to cancel our CONTENTdm subscription and convert these collections to another platform? I was charged with investigating our options.
2 My Parameters
Simulating a budget crisis, I had to use resources we would have on hand. Similarly, I chose methods that would allow me to quickly migrate the collections onto a new platform. This limited my tools to PHP, Perl, and a previously installed instance of XTF. We use XTF as the platform for our digital collection of deposited electronic Illinois state documents. I am more comfortable with Perl than PHP so I defaulted to that as my primary programming language.
XTF is a useful choice for Illinois libraries as it is also used by the Chicago Collections Consortium. There is a large and dedicated users group in Chicago that could lend assistance or implementation advice if needed.
3 The Test Data
Since we are a hosted site, I asked CONTENTdm Support to tar together the images of three collections and place them on an FTP site. These collections, listed below, were selected because I was familiar with the metadata and they represented a reasonable cross section of IDA collections.
- A simple collection of images (one to one relationship of metadata to object) — The Springfield Aviation Company Collection.
- A simple collection of compound objects (a flat, regular, one to many collection of metadata to objects) — The Music of the First World War.
- A complex collection of compound objects (variable, one to many collection of metadata to objects) — The Illinois State Library's General Collection.
OCLC staff provided me with three tarballs of these collections. I exported the metadata in each of these collections though the CONTENTdm administration site as custom XML files. I chose this method so I could edit the element names to make the resulting records easier to manipulate:

4 First Conversion
The Springfield Aviation Company Collection was my first target. I wrote a Perl program to parse the exported monolithic metadata file into separate XML records (Appendix One).
The resulting XML records were transformed into:
<metadata>
<record>
<xmlFileName>11</xmlFileName>
<cdmCode>linl</cdmCode>
<title>Navy V-5 elementary class</title>
<creator></creator>
<contributor></contributor>
<subjectLCSH>Air pilots--United States</subjectLCSH>
<subjectLocal>Springfield Aviation Company; Municipal Airport</subjectLocal>
<browseTopic>Transportation & Communication; Wars & Military</browseTopic>
<description>Students (left to right) DeWall, Spindler, Weber, Allender, Shroyer, Malerick, Broughton, Fisherkeller, Downes, at Municipal Airport, Springfield, Illinois. [Summer 1942]</description>
<dateOriginal>1942</dateOriginal>
<date>1942</date>
<timePeriod>1940s (1940-1949)</timePeriod>
<source></source>
<isPartOf>Sangamon Valley Collection, Southwest Airport Collection, Box 2, Folder 4</isPartOf>
<language></language>
<geographicCoverage>United States--Illinois--Sangamon County--Springfield</geographicCoverage>
<contributingInstitution>Lincoln Library</contributingInstitution>
<rights>Contact Lincoln Library, 327 South 7th Street, Springfield, Illinois, (217) 753-4900 for information concerning copyright restrictions applying to the use or reproduction of this image.</rights>
<dateDigital>2004-06-10</dateDigital>
<identifier>llsa0012</identifier>
<type>Image</type>
<format>Photograph</format>
<digitalFormat>JPEG</digitalFormat>
<digitizationSpecifications>TIFF images created with CanoScan 9900F scanner, 300 DPI, grayscale, ArcSoft Photo Studio 5</digitizationSpecifications>
<transcript></transcript>
<tag></tag>
<collectionName>Springfield Aviation Company Collection</collectionName>
<itemURL>http://cdm16614.contentdm.oclc.org:80/cdm/ref/collection/linl/id/28</itemURL>
<OCLCNumber></OCLCNumber>
<dateCreated>2004-11-15</dateCreated>
<dateModified>2009-12-02</dateModified>
<cdmNumber>28</cdmNumber>
<cdmFileName>29.jpg</cdmFileName>
<cdmFilePath>/linl/image/29.jpg</cdmFilePath>
</record>
</metadata>
I then created the necessary indexing rules in XTF to create a viable index of the collection and indexed the XML records. The XTF instance can be found here. The thumbnails in the brief record display are found in the <cdmFileName> element. The JPEG icon file itself is found by simply adding "icon" to the <cdmFileName> value, icon29.jpg in the above example.
I opted to build Perl programs for the full record display. The full record is linked to the title element display in the brief record (Appendix Two). The information I pass to the full record Perl program is the XML record number and the collection name.
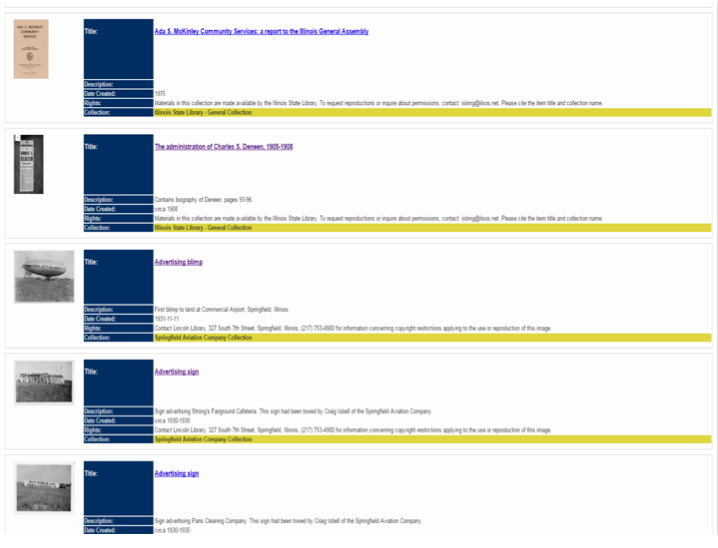
The full record is built in two parts. The first part is a simple text file, named {collection name}.txt, which translates the XML element names into more descriptive text. linl.txt consists of:
title:Title
subjectLCSH:Subjects (LCSH)
subjectLocal:Subjects (Local)
description:Description
dateOriginal:Original Date
sectionHead:Contributed By
contributingInstitution:Contributor
rights:Rights
isPartOf:Collection
identifier:ID Number
sectionHead:Technical Information
dateDigital:Date Digitized
digitizationSpecifications:Specifications
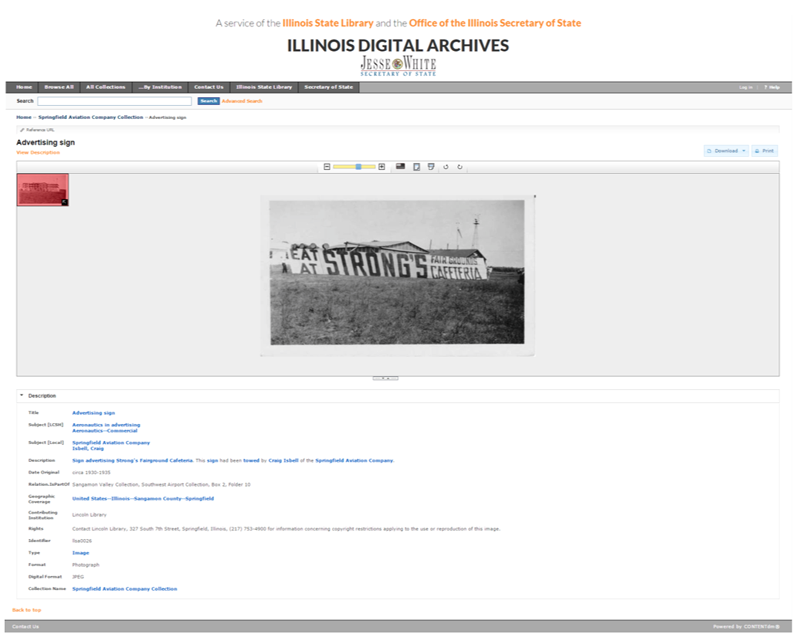
The sectionHead tag indicates a display header, intended to organize the information on the screen in a more logical manner. Below is a screen shot of the result. View the live record here.

Shown below is its IDA/CONTENTdm counterpart. View the live record here.
5 Second Conversion
My second test collection was The Music of the First World War. This collection, from the Pritzker Military Museum and Library, consists of flat, regular records of compound objects. Each record consists of five parts, a JPEG cover image, a PDF of a whole musical score, and MP3, AIFF, and MIDI copies of the digitized music.
CONTENTdm's export yielded these compound objects in two parts. The first part is the metadata itself and the second is an XML file that points to the actual digital objects. The metadata XML record looks like:
<title>While you're over there in no man's land : I'm over here in lonesome land</title>
<composer>Stanley, Jack</composer>
<lyricist>Spiess, Jessie</lyricist>
<performer></performer>
<description>Published by:: Will Rossiter : Chicago, IL</description>
<created>1918</created>
<identifier>M1645 .S8 W5 1918X</identifier>
<relation></relation>
<rights>Access to materials is solely intended for personal use. Other uses of the file and its content, whether commercial, noncommercial, educational, or promotional, may be prohibited without the written permission of the copyright owner, the Pritzker Military Museum & Library. Please contact us at 104 S. Michigan Ave., Chicago, IL 60603, Phone: 312.374.9333.</rights>
<identifier>23915209</identifier>
<provenance></provenance>
<contributingInstitution>Pritzker Military Museum & Library: The Music of the First World War</contributingInstitution>
<fullResolution></fullResolution>
<cdmid>51</cdmid>
<cdmaccess></cdmaccess>
<cdmcreated>2016-03-17</cdmcreated>
<cdmmodified>2016-03-17</cdmmodified>
<cdmoclc></cdmoclc>
<cdmfile>52.cpd</cdmfile>
<cdmpath>/p16614coll23/image/52.cpd</cdmpath>
<thumbnailURL>http://server16614.contentdm.oclc.org/cgi-bin/thumbnail.exe?CISOROOT=/p16614coll23&CISOPTR=51</thumbnailURL>
<viewerURL>http://cdm16614.contentdm.oclc.org:80/cdm/ref/collection/p16614coll23/id/51</viewerURL>
<structure>
<page>
<pagetitle>Front Cover</pagetitle>
<pageptr>46</pageptr>
<pagefile>
<pagefiletype>thumbnail</pagefiletype>
<pagefilelocation>http://server16614.contentdm.oclc.org/cgi-bin/thumbnail.exe?CISOROOT=/p16614coll23&CISOPTR=46</pagefilelocation>
</pagefile>
...
Etc.
The <cpdfile> element points to an XML file that contains pointers to the actual digital objects:
<cpd>
<type>Document</type>
<page>
<pagetitle>Front Cover</pagetitle>
<pagefile>47.jp2</pagefile>
<pageptr>46</pageptr>
</page>
<page>
<pagetitle>AIFF File</pagetitle>
<pagefile>48.aif</pagefile>
<pageptr>47</pageptr>
</page>
<page>
<pagetitle>MIDI File</pagetitle>
<pagefile>49.mid</pagefile>
<pageptr>48</pageptr>
</page>
<page>
<pagetitle>MP3 File</pagetitle>
<pagefile>50.mp3</pagefile>
<pageptr>49</pageptr>
</page>
<page>
<pagetitle>Whole Score</pagetitle>
<pagefile>51.pdf</pagefile>
<pageptr>50</pageptr>
</page>
</cpd>
For ease of display for this test simulation, I decided to convert the JPEG2000 formatted files into conventional JPEG files. Were I doing this in a real situation, I would install djatoka as a Tomcat webapp so that I properly handle JPEG2000 files (see Chute & Van de Sompel, Introducing djatoka, D-Lib Magazine, 2008). I converted the JPEG2000 files using Imagemagick for this test instance.
I opted to concatenate the two XML files into one file for ease of indexing and full record display. I wrote a Perl program that brought the two parts together. The resulting XML file looks like:
<metadata>
<record>
<xmlFileName>14</xmlFileName>
<cdmCode>p16614coll23</cdmCode>
<title>Somewhere in France : (is the Lily)</title>
<composer>Howard, Joseph E.</composer>
<lyricist>Johnson, Philander Chase</lyricist>
<performer>Howard, Joseph E.</performer>
<description>Published by:: M. Witmark & Sons (New York, NY)</description>
<created>1918</created>
<identifier>M1646 .H693 S66 1917S</identifier>
<relation>https://en.wikipedia.org/wiki/Somewhere_In_France_Is_the_Lily</relation>
<rights>Access to materials is solely intended for personal use. Other uses of the file and its content, whether commercial, noncommercial, educational, or promotional, may be prohibited without the written permission of the copyright owner, the Pritzker Military Museum & Library. Please contact us at 104 S. Michigan Ave., Chicago, IL 60603, Phone: 312.374.9333.</rights>
<identifier>71145786</identifier>
<provenance></provenance>
<contributingInstitution>Pritzker Military Museum & Library: The Music of the First World War</contributingInstitution>
<fullResolution></fullResolution>
<cdmid>129</cdmid>
<cdmaccess></cdmaccess>
<cdmcreated>2016-03-18</cdmcreated>
<cdmmodified>2016-03-18</cdmmodified>
<cdmoclc></cdmoclc>
<cdmfile>130.cpd</cdmfile>
<frontPage>125.jp2</frontPage>
<aiffFile>126.aif</aiffFile>
<midiFile>127.mid</midiFile>
<mp3File>128.mp3</mp3File>
<pdfFile>129.pdf</pdfFile>
< cdmFileName>125.jpg</cdmFileName>
<cdmpath>/p16614coll23/image/130.cpd</cdmpath>
<thumbnailURL>http://server16614.contentdm.oclc.org/cgi-bin/thumbnail.exe?CISOROOT=/p16614coll23&CISOPTR=129</thumbnailURL>
<viewerURL>http://cdm16614.contentdm.oclc.org:80/cdm/ref/collection/p16614coll23/id/129</viewerURL>
<structure>
<page>
<pagetitle>Front Cover</pagetitle>
<pageptr>124</pageptr>
<pagefile>
<pagefiletype>thumbnail</pagefiletype>
<pagefilelocation>http://server16614.contentdm.oclc.org/cgi-bin/thumbnail.exe?CISOROOT=/p16614coll23&CISOPTR=124</pagefilelocation>
</pagefile>...
Etc.
I can index the <aiffFile>, <mp3File>, etc. elements in XTF:
<xsl:template name="get-p16614coll23-midiFile">
<xsl:choose>
<xsl:when test="/metadata/record/midiFile">
<midiFile xtf:meta="true">
<xsl:value-of select="string(/metadata/record/midiFile[1])"/>
</midiFile>
</xsl:when>
<xsl:otherwise>
<midiFile xtf:meta="true">
<xsl:value-of select="''"/>
</midiFile>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
<xsl:template name="get-p16614coll23-mp3File">
<xsl:choose>
<xsl:when test="/metadata/record/mp3File">
<mp3File xtf:meta="true">
<xsl:value-of select="string(/metadata/record/mp3File[1])"/>
</mp3File>
</xsl:when>
<xsl:otherwise>
<mp3File xtf:meta="true">
<xsl:value-of select="''"/>
</mp3File>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
I can then link to the different parts of the compound object and make them available directly from the brief record:
6 Third Conversion
The third data set was by far the most challenging. It includes a wide variety of material from the Illinois State Library's own collection. Most of the items consist of complex compound objects, and like the second data set, multi-part XML records. The exported parent metadata record looks like:
<title>The beautiful life of Frances E. Willard: a memorial volume</title>
<alternativeTitle></alternativeTitle>
<seriesTitle></seriesTitle>
<creator>Gordon, Anna Adams, 1853-1931</creator>
<contributor></contributor>
<subjectLCSH>Willard, Frances Elizabeth, 1839-1898;</subjectLCSH>
<browseTopic>Famous Illinoisans</browseTopic>
<description></description>
<created>1898</created>
<date>1898</date>
<timePeriod>1890s (1890-1899)</timePeriod>
<source></source>
<isPartOf></isPartOf>
<language>eng</language>
<geographicCoverage>United States--Illinois</geographicCoverage>
<contributingInstitution>Illinois State Library</contributingInstitution>
<rights>Materials in this collection are made available by the Illinois State Library. To request reproductions or inquire about permissions, contact: [email protected]. Please cite the item title and collection name.</rights>
<dateDigital>2004-08-11</dateDigital>
<identifier>4102646</identifier>
<type>Text</type>
<format></format>
<digitalFormat></digitalFormat>
<digitizationSpecifications>TIFF images created with Epson Expression 836XL scanner, 300 DPI, grayscale, Photoshop 7.0</digitizationSpecifications>
<transcript></transcript>
<tag>willard001</tag>
<oclcNumber>06868272</oclcNumber>
<collectionName>Illinois State Library - General Collection</collectionName>
<itemURL>http://cdm16614.contentdm.oclc.org:80/cdm/ref/collection/isl/id/1692</itemURL>
<oclcNumber></oclcNumber>
<dateCreated>2004-11-15</dateCreated>
<dateModified>2010-06-08</dateModified>
<cdmNumber>1692</cdmNumber>
<cdmFileName>1693.cpd</cdmFileName>
<cdmFilePath>/isl/image/1693.cpd</cdmFilePath>
The accompanying compound object XML file:
<cpd>
<type>Document</type>
<page>
<pagetitle>Table of contents</pagetitle>
<pagefile>1256.jpg</pagefile>
<pageptr>1255</pageptr>
</page>
<page>
<pagetitle>List of Illustrations</pagetitle>
<pagefile>1257.jpg</pagefile>
<pageptr>1256</pageptr>
</page>
...
Etc.
I admit to facing a quandary at this point. How could I search within each of these complex documents? My indexing instructions to XTF would account for keywords within the titles, descriptions, etc., but I would miss the terms within each document. One approach would be to export the metadata with the page-level metadata flag checked. The huge resulting file generally contains a page-level transcript element for each page of the compound object:
K. FINANCIAL COSTS AND PERSONAL INJURIES Following is a breakdown of property and personal injury losses, and other costs involved, as a result of the Chicago riots of October 8-11, 1969: Total Payroll and Expenses of Illinois National Guardsmen, paid by the State of Illinois Building damages Vehicle damages Medical costs of injured policemen * Other medical costs Wages paid during policemen's sick leave Wages paid during Asst. Corporation Counsel Richard Elrods hospitalization Total $100,424.42 34,569.17 3,795.00 3,265.87 19,490.91 6,131.62 15,405.00 $183,081.99 * As of February 4, 1970 1. National Guardsmen The State of Illinois, through the office of the Auditor of Public Accounts, reimbursed the Illinois National Guardsmen for their payroll and expenses for their services during the Chicago riots, as follows: Payroll from October 9-11, 1969 Food Gasoline laundry Travel Repairs Miscellaneous $ 86,872.70 12,366.23 675.25 248.40 18.86 55.03 187.95 $100,424.42 Total 31
</transcript>
I could then concatenate the data from each <transcript> element for each item in the collection and place it into one single large <transcript> element in the XML record. Instead, I opted for a second approach. I concatenated the XML data from the two halves of the record into one XML file:
<metadata>
<record>
<xmlFileName>131</xmlFileName>
<cdmCode>isl</cdmCode>
<title>A museum, a home, a treasure: the Illinois Executive Mansion</title>
<alternativeTitle></alternativeTitle>
<seriesTitle></seriesTitle>
<creator>Illinois Executive Mansion Association</creator>
<contributor></contributor>
<subjectLCSH>Illinois Executive Mansion (Springfield, Ill.); Historic buildings--Illinois--Springfield; Springfield (Ill.)--Buildings, structures, etc.--History</subjectLCSH>
<browseTopic>Illinois History & Culture</browseTopic>
<description></description>
<dateOriginal>1999</dateOriginal>
<date>1999</date>
<timePeriod>1990s (1990-1999)</timePeriod>
<source></source>
<isPartOf></isPartOf>
<language>eng</language>
<geographicCoverage>United States--Illinois--Sangamon County</geographicCoverage>
<contributingInstitution>Illinois State Library</contributingInstitution>
<rights>Materials in this collection are made available by the Illinois State Library. To request reproductions or inquire about permissions, contact: [email protected]. Please cite the item title and collection name.</rights>
<dateDigital>2008-03-27</dateDigital>
<identifier>8817702</identifier>
<type>Text</type>
<format></format>
<digitalFormat></digitalFormat>
<digitizationSpecifications>TIFF images created with Epson Expression 836XL scanner, 300 dpi, 24-bit color.</digitizationSpecifications>
<transcript></transcript>
<tag>8817702</tag>
<oclcNumber>42691656</oclcNumber>
<collectionName>Illinois State Library - General Collection</collectionName>
<itemURL>http://cdm16614.contentdm.oclc.org:80/cdm/ref/collection/isl/id/21127</itemURL>
<dateCreated>2016-06-02</dateCreated>
<dateModified>2016-06-02</dateModified>
<cdmNumber>21127</cdmNumber>
<cpd>
<type>Document</type>
<page>
<pagetitle>Front cover</pagetitle>
<pagefile>31060.jpg</pagefile>
<pageptr>21123</pageptr>
</page>...
Etc.
I then wrote a program that brachiated each XML record's <cpd> section, looking for the <pagefile> element, and built a concatenated PDF file from the individual JPEG files using ImageMagick. I also used ImageMagick to convert the JPEG2000 files into JPEGs, as needed. My Perl program used system calls to work with ImageMagick. It did not occur to me until after the fact that, yes, there is a Perl library designed to work with ImageMagick called PerlMagick. I would install and use PerlMagick if I had to do this again. I named the resulting PDF file with the record number of the XML record and added an element to reflect this: <pdfFile>131.pdf</pdfFile>. Building in the indexing rules in XTF allowed me to index the actual content of the created PDF file as well as the XML record.
Having a <cpd> page-level section in the XML record allows me to use the JavaScript library turn.js (free on Github) to load the component JPEG files into a flip book. The resulting screen is shown below. View the live record here.
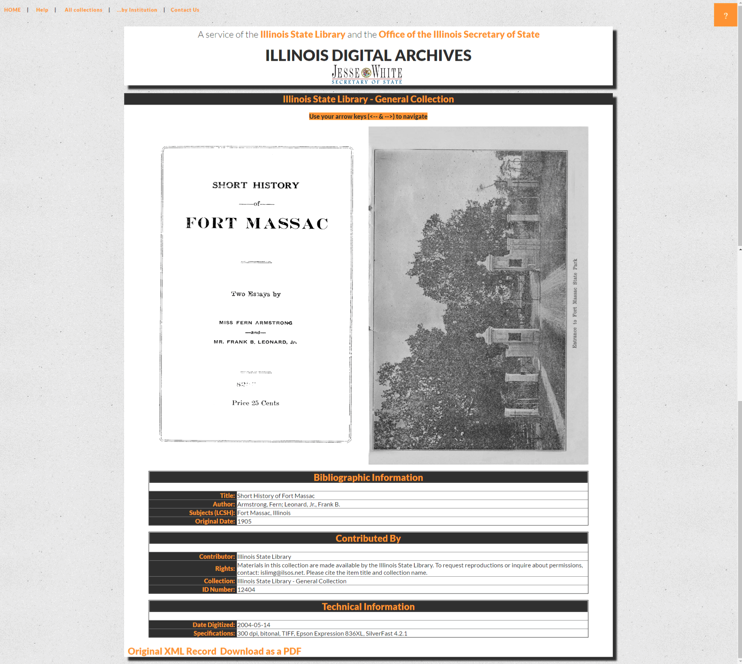
I modified the two loop engine in my xtfFullRecord.pl program to search for a <cpd> section, and, if found, build up a string with each of the <pagefile> values:
for my $property ($sample->findnodes('./*')) {
my $label1 = $property->nodeName();
my $value1 = $property->textContent();
if ($label1 eq "cpd") {
for my $cpd ($property->findnodes('/metadata/record/cpd/page/pagefile')) {
$label2 = $cpd->nodeName();
$value2 = $cpd->textContent();
$pageFile = $pageFile . "<div style=\"background-image:url(http://www.finditillinois.org/flipBook/pages/$value2);\"></div>\n";
}
}
else { $XMLRecord{$label1} = $value1 }
}
}
which generates HTML code:
<div style="background-image:url(http://www.finditillinois.org/flipBook/pages/12389.jpg);"></div>
<div style="background-image:url(http://www.finditillinois.org/flipBook/pages/12390.jpg);"></div>
<div style="background-image:url(http://www.finditillinois.org/flipBook/pages/12391.jpg);"></div>
<div style="background-image:url(http://www.finditillinois.org/flipBook/pages/12392.jpg);"></div>
<div style="background-image:url(http://www.finditillinois.org/flipBook/pages/12393.jpg);"></div>
...
Etc.
I used version 3 of turn.js. Version 4 offers a much larger array of features. As of this writing, licensing version 4 costs $45.00 USD.
7 Conclusion and Lessons Learned
This exercise was a fire drill. As such, there were a number of things I did not fully implement, such as faceted browsing and a proper, unified UX. The point of the exercise was to see if the data could be reasonably converted so I did not pay much attention to design elements. Were I to do this again, I would start with solid UX planning. I would also look at examples of all of the metadata in all of the collections being converted in order to plan what elements can be indexed and how faceted browsing could be implemented. The lack of these two steps resulted in wasted coding time and clumsier programs.
I estimate I spent a total of forty hours on this project, most of it learning how to manipulate the raw XML files and understanding how the structures worked together. Since this was intended as a fire drill, I did not turn to CONTENTdm's support for assistance — I puzzled out the pieces in isolation.
Each collection presented different challenges. Each conversion required custom programming. In planning for a conversion, in addition to UX concerns I would recommend reviewing the metadata elements of each collection and normalizing like elements as much as possible.
I think my approach to including the <cpd> section as part of the XML metadata record is potentially very useful, particularly if one uses the powerful features of version 4 of turn.js (for example, to build a table of contents using the <pagetitle> element). As I mentioned above, I would also install djatoka as a Tomcat webapp so that I could properly handle the component JPEG2000 files.
Were this a real situation, I might also consider using CONTENTdm's APIs as a data transfer medium. CONTENTdm has a number of useful APIs for directly accessing information contained in its indexes and files. I have been working on a cookbook of techniques for using the APIs to manipulate CONTENTdm collections. Please note that neither path — manipulating the XML directly or using CONTENTdm's APIs — is an easy one for conversion.
Finally, I only used part of XTF, and then only in its default mode. The Perl program for full record display, for example, could have been implemented in XSLT. Rowan Brownlee describes how to do this in his excellent tutorial, "Rowan Brownlee's Beginner's Guide to XTF". XTF, or whatever content management system one might use as a backend, should be configured and customized to properly accommodate the exported data set.
Appendix One
my $fileCount = 1;
open (XML, "linlXML.xml");
while (<XML>) {
my $line = $_;
my $a = index ($line, "<record>");
my $b = index ($line, "</record>");
if ($a > -1) {
my $fileName = $fileCount . ".xml";
open (RESULTS, ">$fileName");
print RESULTS "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n";
print RESULTS "<metadata>\n\t<record>\n";
print RESULTS "\t\t<xmlFileName>$fileCount</xmlFileName>\n\t\t<cdmCode>linl</cdmCode>\n";
$fileCount++;
}
elsif ($b > -1) {
print RESULTS "\t</record>\n</metadata>";
close (RESULTS);
}
else { print RESULTS "\t" . $line }
}
close (XML);
Appendix Two
use REST::Client;
use XML::LibXML;
my $query_string = $ENV{'QUERY_STRING'};
my ($uid, $collection) = split (/\&/,$query_string);
my ($junk,$uid) = split (/\=/,$uid);
($junk,$collection) = split (/\=/,$collection);
my @LABELS;
open (LABELS, "$collection.txt");
while (<LABELS>) {
$line = $_;
chomp($line);
push (@LABELS, $line);
}
close (LABELS);
my %XMLRecord;
my $collectionURL = "http://www.finditillinois.org/idaTest/xml/$collection/" . $uid . ".xml";
my $client = REST::Client->new();
$client->GET("$collectionURL");
my $parser = XML::LibXML->new();
my $xmldoc = XML::LibXML->load_xml(
string => $client->responseContent()
);
for my $sample ($xmldoc->findnodes('/metadata/record')) {
for my $property ($sample->findnodes('./*')) {
my $label1 = $property->nodeName();
my $value1 = $property->textContent();
$XMLRecord{$label1} = $value1;
}
}
my $imgURL = "http://www.finditillinois.org/idaTest/img/$collection/images/" . $XMLRecord{'cdmFileName'};
print "Content-type: text/html\n\n";
print <<EOF;
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Illinois Digital Archives :: $XMLRecord{'collectionName'}</title>
<link rel="stylesheet" type="text/css" href="http://www.finditillinois.org/idaTest/css/normalize.css" />
<link rel="stylesheet" type="text/css" href="http://www.finditillinois.org/idaTest/css/demo.css" />
<link rel="stylesheet" type="text/css" href="http://www.finditillinois.org/idaTest/css/component.css" />
<link rel="stylesheet" type="text/css" href="http://www.finditillinois.org/idaTest/css/searchBox.css" />
<script src="http://www.finditillinois.org/idaTest/js/modernizr.custom.js"></script>
<script language="javascript">
function switchMenu(obj) {
var el = document.getElementById(obj);
if ( el.style.display != 'none' ) {
el.style.display = 'none';
}
else {
el.style.display = '';
}
}
</script>
</head>
<body>
<!-- Top Navigation -->
<div class="codrops-top clearfix">
<div class="column">
<div id="sb-search" class="sb-search fixed">
<form method="GET" action="">
<input class="sb-search-input" placeholder="Search the Illinois Digital Archives" value="" name="keyword" id="search">
<input class="sb-search-submit" type="submit" value="Search!">
<span class="sb-icon-search"></span>
</form>
</div>
</div>
<p />
<a href="http://www.idaillinois.org/">HOME</a> | <a href="http://www.idaillinois.org/ui/custom/default/collection/default/resources/custompages/about/help.php" target="new">Help</a> | <a href="http://www.idaillinois.org/ui/custom/default/collection/default/resources/custompages/bin/allInstitutions.php">All collections</a> | <a href="http://www.idaillinois.org/ui/custom/default/collection/default/resources/custompages/bin/byInstitution.php"> ...by Institution</a> | <a href="mailto:islimg\@ilsos.net">Contact Us</a>
</div>
<header class="codrops-header">
<h1><span>A service of the <strong><a href="https://www.cyberdriveillinois.com/departments/library/">Illinois State Library</a></strong> and the <strong><a href="https://www.cyberdriveillinois.com/">Office of the Illinois Secretary of State</a></strong></span>ILLINOIS DIGITAL ARCHIVES</h1>
<a href="https://www.cyberdriveillinois.com/" target="new"><img src="http://www.idaillinois.org/ui/custom/default/collection/default/resources/custompages/img/librarytitleseal.png" width="180px"/></a>
<p />
</header>
<p />
<section class="grid-wrap">
<p />
<h2 style="color: #f7941d; background-color: #333333; text-align: center">$XMLRecord{'collectionName'}</h2>
<p />
<center>
<img src="$imgURL" title="$XMLRecord{'description'}" alt="$XMLRecord{'title'}" width="80%" />
</center>
<p />
<center>
EOF
my $tableCount = 0;
foreach my $labelName (@LABELS) {
my ($labelName, $realName) = split (/\:/,$labelName);
if ($labelName eq "sectionHead") {
if ($tableCount > 0) { print "</table>\n" }
$tableCount++;
print "<p /><table width=\"90%\" border=\"1\">\n";
print "<tr>\n<td colspan=\"2\" width=\"100%\">\n";
print "<h2 style=\"color: #f7941d; background-color: #333333; text-align: center\">$realName</h2>\n";
print "</td>\n</tr>\n";
}
else {
print "<tr>\n<td bgcolor=\"#333333\" width=\"20%\" align=\"right\"><strong style=\"color: />#f7941d;\">$realName:</strong> </td>\n";
print "<td width=\"80%\">$XMLRecord{$labelName}</td>\n</tr>\n";
}
}
print <<EOF1;
</table>
</center>
<p />
<h2 style=\"margin-left: 10px;\"><a href="$collectionURL">Original XML Record</a></h2>
<p />
</section>
</div>
<!-- /container -->
<script src="http://www.finditillinois.org/idaTest/js/uisearch.js"></script>
<script>
new UISearch( document.getElementById( 'sb-search' ) );
</script>
<script>
new GridScrollFx( document.getElementById( 'grid' ), {
viewportFactor : 0.4
} );
</script>
</body>
EOF1
print "</html>\n";
About the Author
Andrew Bullen is the Information Technology Coordinator at the Illinois State Library (ISL). Among his other responsibilities is the technical management of the digital information systems at ISL. His CV can be found here.
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |