|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
May/June 2015
Volume 21, Number 5/6
Statistical Translation of Hierarchical Classifications from Dewey Decimal Classification to the Regensburger Verbundklassifikation
Markus Michael Geipel
German National Library
markus.geipel@alumni.ethz.ch
DOI: 10.1045/may2015-geipel
Abstract
Classification systems are a cornerstone for knowledge organization as well as search and discovery in libraries, museums and archives. As different systems co-exist, translations are pivotal for cross-collection searches. This paper presents a novel approach for statistical translation of hierarchical classification systems. The translation is optimized for application in search and retrieval scenarios. Salient features are: efficient exploitation of the information implied by the classification hierarchy, scalability, and inherent protection against over-fitting. The approach has been used to translate the Dewey Decimal Classification to the Regensburger Verbundklassifikation based on a snapshot of German and Austrian library catalogs.
1 Introduction
Ever since humanity started to preserve intellectual works, there has been the question how to bring order to ever growing collections. The first alphabetical order (respective to the name of the author) is attributed to Kalimachos, a 2000 BC librarian from Alexandria. Semantic, topic wise orderings have been devised by Aristotle, Francis Bacon, John Locke and Gottfried Wilhelm Leibniz [30]. One of today's major hierarchical classification system is the Dewey Decimal Classification (DDC) proposed by Melvil Dewey in 1876 [9]. Since then DDC has been translated in various languages and constantly updated (See the 3rd volume, edition 23 for the current state [28]). The core idea is to assign a number to each concept. Each additional digit narrows down the scope, thus creating a hierarchy: 3 Social sciences ⊃ 33 Economics ⊃ 332 Financial economics ⊃ 332.4 Money. The dot is inserted to enhance readability and has no further semantics1. DDC is not the only classification used by libraries today. A close relative is the Universal Decimal Classification (UDC) [27]. Many but not all German libraries order their collections based on the Regensburger Verbundklassifikation [20]2 (RVK). Besides hierarchical classifications there exists also a large number of non-hierarchical systems based on subject headings.
The plethora of classification systems and thesauri impedes efforts to offer unified search and discovery across collections, databases and institutions. In the German and Austrian library ecosystem, a particular challenge is the coexistence of DDC and RVK. Translations are needed to augment records or to seamlessly expand queries for cross-collection searches. Given the size and complexity of classification systems, a manual translation (also referred to as intellectual translation) is tedious and costly. An alternative to intellectual translation is statistical translation, where for instance, co-occurrence information of classifications in catalog data is exploited.
To produce solid statistical translations, several challenges have to be mastered: Firstly, a "Rosetta Stone", a multilingual corpus is needed. Completely multilingual catalogs are rare. However, as catalogs overlap — especially the German ones [22] — a multilingual corpus can be created by combining catalogs and matching duplicate records.
Secondly, the meaning of the term "translation" needs to be defined in a way that allows for algorithmic search and optimization. While there is an extensive literature dealing with machine translation of natural language offering a wealth of frameworks and definitions, the field of classification translation is less well developed. The challenge is to find a viable framing of the translation problem.
Thirdly, given the framing and a measure of goodness, a suitable translation algorithm is needed to find optimal or near optimal solutions.
Finally, classification systems such as DDC, UDC or RVK are hierarchical. This means that a given class implies a whole list of classes which are chained together by hypernym relationships. Only counting co-occurrences and ignoring the hierarchical context of a class would thus neglect a vast part of the available information. Making efficient use of hierarchies is a critical success factor.
All these challenges are addressed in this paper, with the translation from DDC to RVK and vice versa as a concrete application. After a survey of related work, Section 3 presents the library catalogs that served as input data. In Section 4 the translation problem is formalized and the translation algorithm is developed. Section 5 discusses the results. Options for further enhancements are sketched in Section 6. Finally, a conclusion is drawn in Section 7.
2 Related Work
The work presented in this paper takes its cues from a number of fields: There are a lot of parallels between the translation of classifications and the well established field of natural language processing, and statistical machine translation in particular. For an overview see [25] and [1].
Of special importance in the context of thesauri and classification translation is the work of Church and Gale [7]. It proposes algorithms for the automated construction of a bilingual dictionary based on parallel texts. A recent application of these methods to classifications and thesauri was presented by Lösch et al. [21] who constructed a corpus of DDC-annotated documents and related terms in the text with DDC categories by means of chi-square analysis. Section 4 will revisit these tools.
Furthermore, Brown et al. [4] pioneered the framing of translation as an optimization problem. They take a Baysian approach and present probability models for translations. The maximized quantity is therefore the probability of a translation in context of the empirical data. The idea to model translation as an optimization problem will be the cornerstone of Section 4. The approach, however will not be a Bayesian one but will take an information retrieval point of view: The F-measure is maximized, not probability.
Besides the general literature on statistical machine translation, there has been a strand of research dealing particularly with translations of thesauri and classification systems. An important point of reference is ISO standard 5964 "Thesauri and interoperability with other vocabularies" [16], and the upcoming part 2 "Interoperability with other vocabularies" in particular. The standard provides a solid reference framework by defining a clear set of possible relationships between terms of different thesauri. These definitions mark the starting point of Section 4. For more information on the genesis of ISO 5964 see also [10].
Thesaurus translations in the library domain have mainly been constructed intellectually, in sharp contrast to the algorithmic, quantitative approach presented in this paper. For a discussion of the challenges of intellectual translation and metadata interoperability see the work of Doerr [11] as well as Zeng and Chan [36, 37].
A project of international importance in the field of thesaurus translation is the Multilingual Access to Subjects (MACS). MACS is a cross-walk between the subject heading thesauri of the Library of Congress (LCSH), the French National Library (RAMEAU) and the German National Library (GND). All three thesauri are non-hierarchical in the sense that neither id nor label do imply hierarchical relationships3. MACS is an example of an intellectually constructed translation. Further information can be found in [8, 18]. Another example of an intellectual translation is project CrissCross [2]. Its goal was to create a crosswalk between DDC and GND. One major challenge was to correct alignment of the non-hierarchical, network oriented GND to the hierarchical classification system of DDC.
There have also been several approaches to automatic translations. Larson [19] evaluated several methods for automatic assignment of Library of Congress Classification labels (LCC) based on title and subject headings of a document. Such an approach is often called "lexical" matching because the lexical information in class labels, description and document titles is used. See for instance the work of Malaise et al. [23] for more recent efforts along these lines. In contrast to lexical methods, Vizine-Goetyz [32] uses co-occurrence data and the log-likelihood ratio to measure the association between LCSH and DDC. Such approaches are often called instance-based. In that sense also the algorithm presented in Section 4 is instance-based.
Several studies are dedicated to the evaluation of the different automatic translation approaches: The study of Wang et al. [33] contrasts a lexical with statistical/instance-based approach while, Isaac et al. [15] explore the merits of different similarity measures for matching subject headings: e.g. the Jaquard measure and information gain. Furthermore, the F-measure is used to compare automatic translations with a manually generated reference data set. In the same vein, Mayr and Petras [26] emphasize the use of translations in search, and argue in favor of the F-measure as a means to assess the quality of a manually constructed translation. In Section 4.1 this line of thought is extended to algorithmic translation.
Finally, as pointed out in the introduction, the hierarchy within DDC and RVK is a valuable source of information. Several authors have likewise emphasized its important role: Thompson et al. [31] used the DDC hierarchy to increase the matching rate in automatic subject assignment. Weigend et al. [34] report on the benefits of exploiting hierarchy when categorizing texts by means of neural networks. Finally, Frank and Paynter [13] emphasize the importance of hierarchy for predicting Library of Congress Classification labels (LCC) based on subject headings. The classifiers in this case were constructed with linear support vector machines.
3 Bilingual Corpus Creation
The calculation of a statistical translation hinges on the availability of a bilingual corpus. In the search for a translation between DDC and RVK, the federal nature of the German library world turns out to be a boon: Some of the catalogs, including the one of the National Library are using DDC, while some are using RVK, and some use both. There is considerable overlap between the catalogs. The overlap provides an opportunity to enrich records containing DDC with the respective RVK of matching records from other catalogs and vice versa. The matching itself is not trivial, though: Bibliographic data tends to be noisy and cataloging standards vary over time and from institution to institution. Finally, given the amount of data, any matching algorithm must by efficient in terms of run time complexity.
In the following subsection, the bibliographic data set is introduced, followed by a description of the matching logic and its implementation.
3.1 Data Set
The data used for the translations was collected in the context of the project Culturegraph. By the time of writing of this paper it comprised 120 million records from the German National Library (DNB), Five German library networks — Bayerischer Bibliotheksverbund (BVB), Südwestdeutscher Bibliotheksverbund (BSZ), Gemeinsamer Bibliotheksverbund (GBV), Hochschulbibliothekszentrum Nordrhein-Westfalen (HBZ) and Hessisches BibliotheksInformationsSystem (HEB) — and the Austrian library network Österreichischer Bibliotheksverbund (OBV).
Table 1 summarizes the data set sizes and the occurrences of DDC and RVK. The data was delivered between July and November 2012, except for the HEB data which dates from October 2011. The records in the data set are not restricted to books but describe a variety of media types. Books are the majority, though.
Table 1: Numbers of records, total and classified.
| #records | DDC | RVK | both | |
| BSZ | 17,344,946 | 3,178,023 | 4,111,081 | 1,371,168 |
| BVB | 23,824,598 | 2,501,526 | 5,833,517 | 1,533,029 |
| DNB | 13,248,434 | 672,683 | 1,364 | 146 |
| GBV | 35,354,555 | 4,604,907 | 928,018 | 611,802 |
| HBZ | 18,198,794 | 263,755 | 1,091,763 | 21,780 |
| HEB | 6,147,976 | 284,864 | 2,380,254 | 117,871 |
| OBV | 8,562,686 | 413,016 | 744,356 | 94,608 |
| 122,681,989 | 11,918,774 | 15,090,353 | 3,750,404 | |
3.2 Bundling of Records
The catalogs of the different library networks included in Culturegraph exhibit significant overlap, which gives us the chance to increase the number of "bilingual" records by matching duplicates.
The matching algorithm relies on three matching criteria. Records are bundled if either of these three is satisfied. The algorithm calculates the transitive hull of the equivalences, meaning that the bundling splits the data set in nonoverlapping bundles.
The criteria are the following; records are bundled if one ore more of the following criteria is true:
- one ISBN4, volume number, year and edition number match.
- EKI5, volume number, year and edition number match.
- normalized title, one normalized author name, volume number, year and edition number match.
The matching criteria were coded in the domain specific metadata transformation language Metamorph [14]. The actual Metamorph script contains several further normalization steps which are beyond the scope of this paper. The script is published at GitHub here. To cope with the large amount of data, the matching was run on a Hadoop cluster. The Java code for the respective cluster jobs is published here under the Apache 2 license.
When counting evidence for co-occurrence in this new corpus, we need to exercise caution. A naive approach would count all co-occurrences in the corpus. This method however would repeatedly recount the same evidence. Let us assume that four records are bundled: Two are classified DDC 332 Financial Economics, the next two are classified RVK QC 320 Monetary Theory and QM 300 Balance of Payments, respectively. After bundling and enrichment, each of the four records is classified 332 ∪ QC 320 ∪ QM 300. The co-occurrence of 332 and QC 320 would be counted four times. The evidence for such a co-occurrence is only two, though: Two documents bearing 332 came together with one bearing QC 320.
To avoid such spurious counts, two separate data sets are constructed; one for the translation DDC → RVK and one for RVK → DDC: The DDC → RVK data set only contains documents originally classified with DDC, enriched with RVK classification via the bundling. For the RVK → DDC data set it is the other way round. Co-occurrence counts are therefore never overestimated. The resulting sets have 7,056,463 and 5,147,555 elements respectively. This constitutes an improvement in size over the naturally occurring bilingual records (see Table 1). Apart from this increase, the bundling algorithms also adds further options to influence the translation result (see final discussion in Section 7).
4 Translation
To approach classification translation as an optimization problem, a formal framing is needed. A solid stating point is the ISO standard 25964 [16] mentioned before: "Information and documentation — Thesauri and interoperability with other vocabularies". Part II discusses the possible relationships between terms of different thesauri. The key insight is that one-to-one translations are the exception. Due to the different ways of dividing and modeling the domains of human knowledge adopted by the various classification systems, compound equivalence is the rule. In other words, translations form one-to-many or many-to-many relationships. Compounds can be intersecting or cumulative, meaning that a single concept in one thesaurus may correspond to an intersection or the union of concepts from another thesaurus; and vice versa.
In the case of hierarchical classification systems, the possibilities of combination are a slightly more limited, though. By definition the classes in one level of the hierarchy are non-overlapping. This means that a translation can be constructed by finding the appropriate union of classes in the respective target classification. Here is an actual example:
The DDC class Financial Economics is translated to the union of the RVK classes for Monetary Theory and Balance of Payments. A cross-collection search engine would use this translation as follows: The user issues a query for documents classified with DDC 332. The query interpreter automatically expands the query to 332 ∨ QC 320 ∨ QM 300. The query will thus also retrieve documents dealing with Financial Economics, lacking the respective DDC classification.
The remainder of this Section is organized as follows: To algorithmically produce good translations, "goodness" needs to be operationalized. Section 4.1 provides the details. Section 4 then presents an algorithm to actually calculate the translation. Finally, Section 4.3 explains how the hierarchical structure of DDC and RVK is exploited in the calculations.
4.1 Desirable Properties of a Translation
A translation between two classification systems may be optimized with respect to a variety of properties. Given the purpose of the translation between DDC and RVK developed in this paper — seamless cross-collection searches — the following two properties had a significant impact on the design of the algorithm.
Firstly, it is important, that a query using a translation of class c retrieves almost the same documents as c itself. The next subsection discusses this result-set-similarity further. Secondly, a translation should be concise: Translating a DDC class c to the union of a large number of RVK classes of narrow scope, has a several disadvantages even though the result-set-similarity might be high. Section 4.1.2 elaborates on this.
4.1.1 Result-Set-Similarity
As already pointed out, translations are indispensable for offering search and discovery services for heterogeneously classified collections. With respect to this objective, the F-measure is a pragmatic and expedient indicator for the goodness of a given translation. It is the standard choice for evaluating success in information retrieval systems [1, 24] and has also been used for estimating the quality of intellectual thesaurus translations as already pointed out in Section 2.
Note that in the following the F-Measure is not used to evaluate the results ex post (as in [1, 24]), but becomes an input to the translation algorithm.
The F-measure is the harmonic mean of precision and recall, which in turn may be easily defined based on queries using the class to be translated s and its translation T. As pointed out before, a translation T consists of a set of classes in the target classification system. Taking example (1) above, s would correspond to 332 and T to the classes QM320 and QM300.
The function query returns the media units satisfying the logical expression provided as argument.
Precision is thus the fraction of media units being classified s out of those found by searching for T. For instance, recurring to example (1)S: if a query for (QM320 ∨ QM30) returns 100 hits and a query for ((QM320 ∨ QM300) ∧ 300) returns 80, the precision is 0:8: 80% of the records retrieved with the translation were actually relevant in the sense that they were classified with class 300.
In the same vein we define recall:
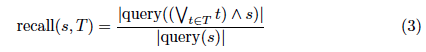
Recall is thus the fraction of all media units in the corpus classified s which are retrieved by using T as search term. Assuming that a query for 300 returns 200 hits and a query for ((QM320 ∨ QM300) ∧ 300) returns 80, the recall is 0:4: The translation was only able to retrieve 40% of all records classified with class 300.
Neither precision nor recall alone is enough, though. For instance, a recall of 1:0 could easily be achieved by simply adding all classes of the classification system to T, thus retrieving all media units in the corpus, and thus by definition retrieving all media units classified as s. The solution is to use the harmonic mean of precision and recall as it penalizes lopsided optimization for either one:
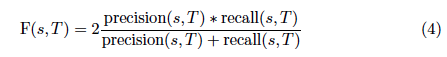
A high F-measure means that the search results for s can be approximated well with a search for T. That is what we expect from a translation used for searches in a corpus labeled with different classification systems.
4.1.2 Simplicity
Apart from the F-measure, there is another dimension to consider: Simplicity. As just described, finding a translation, for instance of DDC class 006.3 Artificial Intelligence means finding a set of RVK classes which approximate the result of querying for DDC 006.3. Figure 1 depicts two possible translations in a schematic way.
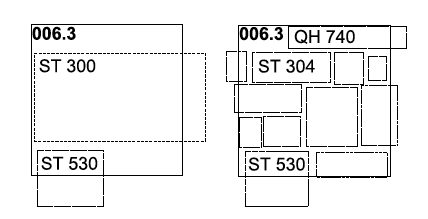
Figure 1: Two possible translations of DDC 006.3 (solid rectangle). Left, with a union of only two broad RVK classes (dotted rectangles). Right with a larger number of narrow RVK classes.
On the left side is shown a translation of 006.3 using two RVK classes of broader scope. On the right side a translation is shown that comprises a larger number of narrowly scoped RVK classes. The right one results in a better F-measure as the result set (depicted as rectangle) is better approximated by the union of the narrow RVK classes (dotted rectangles). In practice, the simpler translation on the left has several advantages: Firstly, a translation which uses a similar level of abstraction is easier to understand for humans. The meaning of a union of a large number of narrow classes is harder to comprehend. Secondly, a simple translation with a small number of broader classes is easier for machines to process: If the translation is used for query expansion to enhance searches, for example, the more complex translation also leads to less efficient searches. Finally, the complex translation is less stable in the face of changing data, as a few co-occurrences changes in narrow classes might easily result in a different translation. For broader classes much more evidence needs to shift to cause a modification of the translation. In other words, over-fitting is avoided by striving for the simpler solution. It is thus common practice in machine learning settings to penalize complex solutions, e.g. by a regularization term. For an in-depth discussion of the importance of regularization see [3] (chapter 1).
4.2 Efficient Search for a Translation
Despite having limited translations to cumulative compound equivalences, the number of possible union sets is vast6. Obviously, an exhaustive search is unfeasible. The next section presents a method to further cut down the number of possible candidates for a translation. Section 4.2.2 proposes an algorithm to generate a translation based on the candidates.
4.2.1 Candidate Classes
Which classes should be considered at all? Clearly, considering the entirety of the target classification is neither feasible nor sensible. Taking for instance a translation from DDC to RVK. In a translation only those RVK classes can be used for which co-occurrence data with DDC classes exists. We can still go further and demand that such a co-occurrence exhibits a certain level of statistical significance.
Filtering of classes by statistical dependence has three advantages: Firstly, it cuts down the search space. Secondly, translations only consist of classes for which there is solid statistical evidence. Thirdly, it protects against over-fitting: The translation will not depend on statistically insignificant noise in the data. See also the arguments in favor of simple translations put forth in Section 4.1.2.
Statistical dependence can be analyzed with Pearson's chi-square test [29], a common technique in the field of statistical natural language processing [12, 25, 35]. The general equation for chi-square (X2) can be simplified for co-occurrence data of only two events as follows:
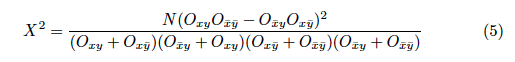
where ![]() denotes the number of observed media units being both in class x and y. Whereas denotes the number of media units being in x but not in y. N is the total number of media units in the corpus.
denotes the number of observed media units being both in class x and y. Whereas denotes the number of media units being in x but not in y. N is the total number of media units in the corpus.
The result of the test is a value of X2. It corresponds to the value of the chi-square distribution with one degree of freedom. A lookup in the distribution table gives us the probability that the observed data was generated by independent events. A low probability is thus an indicator of dependence. In practice a threshold for X2 is chosen. Surpassing the threshold is interpreted as dependence. A value of 10:83, for instance, would be sufficient to assume independence at a 99.9% confidence level. In practice a much higher value is chosen as statistical significance differs from practical significance [5, 6]. With enough data a practically irrelevant level of dependence might already be statistically highly significant. The results presented in Section 5 were calculated with X2 > 100.
4.2.2 Combining Candidates
In the search for a combination of candidates which optimizes the F-measure of the translation we face two facts: Firstly, the F-measure is non-monotonic under the union operation. This means that the union of two translations may result in an F-measure higher than the one exhibited by any of the two original translations. The opposite is equally possible: The union may decrease the F-measure below the original values. This means that a greedy or gradient ascent approach might get trapped in a local maximum. Secondly, evaluating the F-measure of a translation via search queries is costly: A search index is needed, and as will be explained in Section 4.3, it must support trailing wild-card queries. Exhaustive search of all possible unions of the candidate set is unfeasible, except for very small candidate sets: The number of possible unions of n elements is 2n.
Nevertheless, the algorithm shown in listing 1 finds a good compromise between run-time complexity, high F-measure (see Section 4.1.1) and simplicity (see Section 4.1.2).

The basic idea is to use a greedy approach with an initial condition such that the search leads to a local F-measure maximum of low complexity. We assume to have as input the source class (s) to be translated along with a set of candidate target classes (C) selected as described in Section 4.2.1. As a first step, C is sorted by the F-measure in decreasing order (line 1). The second argument to Sort is the comparator function. The F-measure of each candidate can already be precomputed during the filtering by chi-square as both measures are based on the same occurrence and co-occurrence counts. Next, the first candidate is added to the translation (line 2). This means we start the search with the optimal minimum complexity translation. In other words, if s were to be translated to only one class in the target classification, this would be the optimal one. Subsequently, the algorithm tries to add candidates from C to T, with the objective to increase the F-measure of T (lines 4-9).
Finally, to weed out low quality translation, the resulting translation T is checked against a minimum F-measure (lines 9,10). In practice, this step is decoupled from the rest of the algorithm: All translations are written to a file along with their respective F-measure, and the filtering can be conducted later based on the requirements of the respective application scenario.
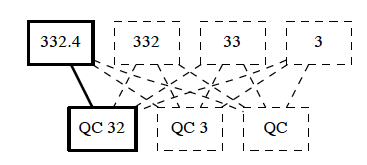
Figure 2: The co-occurrence of the DDC class 332.4 Money and RVK QC 32 Monetary Theory implies further co-occurrences, indicated as dotted lines. For instance RVK QC 32 co-occurs implicitly with DDC 3 Social Sciences. See Section 4.3.
4.3 Exploiting the Hierarchy
As pointed out in the introduction, a class in a hierarchical classification system implies a chain of hypernyms corresponding to the path to the root of the hierarchy7.
Imagine a media unit being assigned to DDC 332.4 Money as well as to RVK class QC 32 Monetary Theory. Figure 2 gives a visual representation. A query for 332.4 would thus also return at least one media unit classified QC 32. This is an explicit co-occurrence (solid line in Figure 2). It implies that a query for DDC 3 Social Sciences, being a hypernym of 332.4, would return at least one media unit classified QC 32. This is one of the implicit co-occurrences (dotted line in Figure 2).
This implied information is of paramount importance for the translation process: As pointed out in the introduction of this Section (4), one-to-one translations are rare, one-to-many translations are the rule. If a class can not be translated directly to a corresponding class at the same level of abstraction, it must be translated to the union of narrower classes. This means that co-occurrence data across different abstraction levels is needed. Bearing the example of Figure 2 in mind, it is evident that co-occurrences at the same level of abstraction are predominantly explicit, while co-occurrences across abstraction levels are predominantly implicit.
The consequences are twofold: Firstly, the chi-square analysis used to detect viable translation candidates (see Section 4) needs to be extended as follows: Let CDDC be the DDC classes a media unit is assigned to. For each c ∈ CDDC all super classes are generated by successively removing the last character/digit. The classes are added to a new set C‘DDC. See Algorithm 2. We proceed the same way with the RVK classes. The new co-occurrence data is then given by the Cartesian product of C‘DDC and C‘RV K.

The second adjustment concerns the calculation of the F-measure discussed in Section 4.1. The queries must not only retrieve exact matches for a class but additionally all matches for subclasses in the hierarchy: Thus, a query for 332.4 must retrieve all documents classified 332.4 as well as all whose classification has 332.4 as prefix. In search and retrieval terms this corresponds to the trailing wildcard query 332.4∗.
5 Discussion of Results
With the data set described in Section 3 and the algorithm described in Section 4 large parts of DDC and RVK can be translated. The exact number depends on the desired minimum F-measure a translation must achieve. Setting this threshold to 0:1 results in 57,117 translations from DDC to RVK and 62,599 translations from RVK to DDC. Figure 3 shows how the number of translations decreases with an increasing threshold for the F-measure.
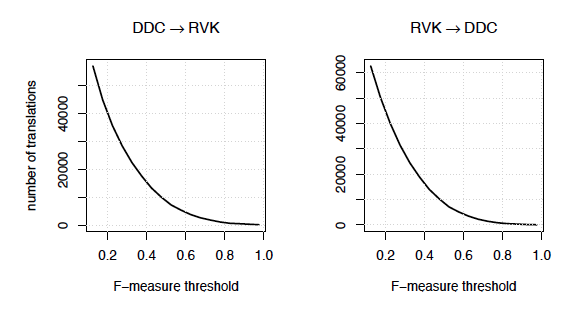
Figure 3: Number of translations dependent on the F-measure threshold.
A preliminary evaluation of the results was conducted by a domain expert with several years of experience in cataloging and classification. It comprised translations at various levels of abstraction taken from two different subject categories: computing (Table 2) and economics (Table 3).
Table 2: Sample of translation results for DDC class 006, along with intellectual evaluation.
| class | label | |
| 006 | Special Computer Methods | |
| > | ST 53 | Data-Warehouse-Concept; Data Mining |
| > | ES 945 | Speech Recognition |
| > | ST 3 | General Artificial Intelligence |
| > | ZN 605 | Pattern Recognition, Image Recognition, Image Processing |
| < | ST 28 | User Interfaces |
| < | ST 253 | Web Programming Tools |
| < | ST 252 | Web Programming in General |
| 006.3 |
Artificial Intelligence |
|
| = | ST 30 | General Artificial Intelligence |
| > | ST 530 | Data-Warehouse-Concept, Data Mining |
| ∅ | ST 283 | Nonexistent. See Section 5. |
| ∅ | ST 286 | Nonexistent. See Section 5. |
| ∅ | ST 285 | Computer Supported Cooperative Work, Groupware |
| 006.31 |
Artificial Intelligence |
|
| = | QH 74 | Learning Process, Theories of Learning |
| > | ST 53 | Data-Warehouse-Concept; Data Mining |
| < | ST 304 | Automatic Programming, Deduction and Theorem Proving, Knowledge representation |
| 006.312 |
Artificial Intelligence |
|
| < | ST 53 | Data-Warehouse-Concept, Data Mining |
Table 3: Sample of translation results for DDC class 332, along with intellectual evaluation.
| class | label | |
| 332 | Financial Economics | |
| = | QK | Money, Credit, Banking, Banking Management |
| > | QC 320 | Monetary Theory |
| > | QM 300 | Balance of Payments |
| ∼ | QP 890 | Financial Mathematics (>), Business Mathematics (∅) |
| 332.4 |
Money |
|
| = | QK 2 | Money, Currency, Monetary Standards |
| = | QC 32 | Monetary Theory |
| > | QK 92 | Instruments of Monetary and Credit Policy |
| < | QK 7 | Prices, Inflation, Deflation |
| ∅ | QM 33 | International Monetary Adjustments (subclasses correct) |
| 332.46 |
Monetary Policy |
|
| = | QK 90 | Monetary Policy, Credit Policy, Central Banks |
| > | QK 92 | Instruments of Monetary and Credit Policy |
In computing the translations range from DDC 006 Special computer methods down to DDC 006.312 data mining: The source class from DDC is printed in bold; below it in normal font are shown the RVK classes comprising the translation. The left column indicates the evaluation result by the domain expert. The meaning of the symbols is as follows:
| = | Both classes correspond to each other both semantically as well as in terms of level of abstraction. |
| > | The class in the translation is conceptually narrower. |
| < | The class in the translation is conceptually broader. |
| ∅ | The classes do not match |
| ∼ | Other. See respective comment in the label column. |
Both '=' and '>' are favorable results: Clearly a semantic correspondence on the same level of abstraction is ideal ('='), though not always possible. The various classification systems use different approaches in modeling the domains of human knowledge which leads to different groupings of topics. A common situation in translation is thus that a class has to be translated into a union of classes with narrower scope ('>'). In some cases this is not possible either. Take for instance the translation of 006.312 Data Mining, (Table 2). RVK only offers ST 53 Data-Warehouse-Concept, Data Mining which has a broader scope ('>'). Of particular interest for evaluations are the mismatches ('∅'), as they point to possible improvements of the algorithm.
The following types of mismatches occur in the preliminary evaluation:
Simple mismatch: In the simplest case, the algorithm adds a class to the translation which does not fit semantically. An example is RVK QM 33 International Monetary Adjustments being part of the translation for DDC 332.4 Money (Table 3). Albeit not completely unrelated, QM 33 is, according to experts, subsumed entirely by DDC 332.152. Another example is RVK ST 285 Computer Supported Cooperative Work, Groupware being part of the translation for DDC 006.3 Artificial Intelligence. Based on the empirical data, it seems that both topics often co-occur. Still, they are semantically separate. One option to remedy such mismatches would be to raise the chi-square threshold. More evaluation data is needed though, to make an informed decision on the appropriate value. We still need to consider the possibility that cataloguing practice deviates from theory, and that some of the mismatches reflect insufficiently defined parts in the respective classification system.
Classes with mixed content: A mismatch that stems from the differences in modeling and splitting up topics in DDC and RVK: 332 Financial Economics, Table 3 was translated to QP 890 Financial Mathematics, Business Mathematics. Part of the class — financial mathematics — would fit, whereas the topic of business mathematics belongs to a DDC class different than 332. Such problems are hard to eliminate as a deep intellectual understanding of the respective classification systems is needed to spot them.
Non-existing classes: The translation of 006.3 Artificial Intelligence (Table 2) comprises the non-existing classes ST 283 and ST 286. This error is due to the fact that RVK uses a technique called Cuttering8, to encode years and author names as postfix of a class. For instance the name "Franck" becomes F822, "Francke" becomes F823. Interpreting ... F822 as a subclass of ... F82 does not make sense. There exist further violations that hierarchy implies hypernymity. An example is DDC class 09 Computer science, information & general works which comprises such diverse classes as 0610 Associations, organizations & museums and 004 Data processing & computer science. The reason for this is that the basic architecture of DDC predates relatively new fields of knowledge such as computer science.
To address this problem, domain experts would need to compile a set of rules or a list that indicates non-hierarchical classes in both DDC and RVK. For all those instances, the exploitation of hierarchy as described in Section 4.3 could then be switched off.
6 Future Prospects
Future lines of research include an in-depth evaluation of the calculated translations by domain experts, followed by optimization of the algorithm. Three different starting points for such optimization are: Firstly, the adjustment of the chi-square threshold as already indicated in Section 5. Secondly, modification of the algorithm presented in Algorithm 1. Thirdly, the input data itself may be changed: As explained in Section 3, the corpus hinges on the matching algorithm used to create bundles of equivalent bibliographic records. A promising venue would be to weaken the definition of equivalence, thus creating larger bundles and more co-occurrences between DDC and RVK classifications. One could argue for instance, that the topic of a book is unlikely to change with edition numbers, and thus edition numbers should be ignored in the matching algorithm. Further quantitative research and involvement of domain experts is planned.
7 Conclusion
In this paper a novel algorithm was presented for translating hierarchical classification systems based on catalog data. It scales to large data sets, efficiently exploits the classification hierarchy and avoids over-fitting. The translation between the classification systems DDC and RVK was discussed in particular. With the corpus of data introduced in Section 3 and the algorithm presented in Section 4, it was possible to translate large parts of DDC to RVK and vice versa. The results reached a high level of quality as shown by a preliminary evaluation performed by a domain expert (Section 5). Further improvements can be expected from the lines of future research sketched in Section 6. All in all, the translations DDC → RVK and RVK → DDC are in their current state already perfectly suitable for search query expansion, and thus are a major step towards seamless cross collection search and discovery in the German and Austrian library network.
Open access to the translation results is provided at: https://github.com/mgeipel/researchresults.
Acknowledgements
The author would like to thank Sandro Uhlmann (German National Library) for the evaluation of the translation results as well as the insightful discussions on DDC and RVK. Furthermore, the author would like to express his deepest gratitude for the detailed feedback and the numerous, valuable suggestions provided by Jan Hannemann (German National Library).
Notes
1 Another syntactic convention it to expand top-level DDC classes with trailing zeros to create a three digit number. In this paper the expansion is omitted to keep the hierarchy level as clearly visible as possible.
2 See also http://rvk.uni-regensburg.de/
3 However, parts of the thesauri are enriched with references to synonyms, hyperonyms, meronyms etc. In that sense they can be considered network oriented.
4 There exist records in the data with multiple ISBNs. Thus, the 'one' means that at least one of them must match. Please further note, that the ISBN alone is not unique. It is supposed to be unique among all books currently in print, but may be recycled once a book is out of print.
5 An identifier specific to the German and Austrian library networks. See here.
6 O(2N) with N being the number of classes in the classification system.
7 See also the DDC related exercises (starting with 2.3-13) in [17].
8 Named after the U.S. librarian Charles Ammi Cutter.
9 Officially written as 000. Top-level DDC classes are expanded with trailing zeros to count at least three digits.
10 Officially written as 060.
References
[1] R. Baeza-Yates and B. Ribeiro-Neto. Modern information retrieval. ACM press New York., 1999.
[2] G. Bee. Crisscross. Dialog mit Bibliotheken, 18(2):23—24, 2006.
[3] C. M. Bishop. Pattern recognition and machine learning. Springer, New York, 1st edition, 2007.
[4] P. F. Brown, V. J. D. Pietra, S. A. D. Pietra, and R. L. Mercer. The mathematics of statistical machine translation: Parameter estimation. Computational linguistics, 19(2):263—311, 1993.
[5] R. P. Carver. The case against statistical significance testing. Harvard Educational Review, 48(3):378—399, 1978.
[6] R. P. Carver. The case against statistical significance testing, revisited. Journal of Experimental Education, 61(4):287—292, 1993. http://doi.org/10.1080/00220973.1993.10806591
[7] K. W. Church and W.A. Gale. Concordances for parallel text. In Proceedings of the Seventh Annual Conference of the UW Centre for the New OED and Text Research, pages 40—62, 1991.
[8] G. Clavel-Merrin. MACS (Multilingual access to subjects): a virtual authority file across languages. Cataloging & Classification Quarterly, 39(1-2):323—330, 2004. http://doi.org/10.1300/J104v39n01_02
[9] M. Dewey. A classification and subject index for cataloguing and arranging the books and pamphlets of a library. Amherst, Mass, 1876.
[10] C. S. G. Dextre and M. L. Zeng. From iso 2788 to iso 25964: The evolution of thesaurus standards towards interoperability and data modelling. Information Standards Quarterly (ISQ), 2012.
[11] M. Doerr. Semantic problems of thesaurus mapping. Journal of Digital Information, 1(8), 2001.
[12] T. Dunning. Accurate methods for the statistics of surprise and coincidence. Computational Linguistics, 19(1):61—74, 1993.
[13] E. Frank and G. W. Paynter. Predicting library of congress classifications from library of congress subject headings. Journal of the American Society for Information Science and Technology, 55(3):214—227, 2003.
[14] M. M. Geipel, C. Böhme, and J. Hannemann. Metamorph, A Transformation Language for Semi-structured Data. D-Lib Magazine, 21(3/4), May/June 2015. http://doi.org/10.1045/may2015-boehme
[15] A. Isaac, L. Van Der Meij, S. Schlobach, and S. Wang. An empirical study of instance-based ontology matching. In The Semantic Web, pages 253—266. Springer, 2007. http://doi.org/10.1007/978-3-540-76298-0_19
[16] ISO 25964. Thesauri and interoperability with other vocabularies. ISO, Geneva, Switzerland, 2011.
[17] D. E. Knuth. The Art of Computer Programming, volume 1. Addison Wesley Longman Publishing Co., Inc., Redwood City, CA, USA, 3rd edition, 1997.
[18] P. Landry. Multilingual subject access: The linking approach of MACS. Cataloging & Classification Quarterly, 37(3-4):177—191, 2004. http://doi.org/10.1300/J104v37n03_11
[19] R. R. Larson. Experiments in automatic library of congress classification. JASIS, 43(2):130—148, 1992. http://doi.org/0.1002/(SICI)1097-4571(199203)43:2<130::AID-ASI3>3.0.CO;2-S
[20] B. Lorenz. Handbuch zur Regensburger Verbundklassifikation: Materialien zur Einführung, volume 55. Otto Harrassowitz Verlag, 2008.
[21] M. Lösch, U. Waltinger, W. Horstmann, and A. Mehler. Building a ddcannotated corpus from oai metadata. Journal of Digital Information, 12(2), 2011.
[22] C. Lux. The german library system: structure and new developments. IFLA Journal, 29(2):113—128, 2003.
[23] V. Malaisé, A. Isaac, L. Gazendam, and H. Brugman. Anchoring dutch cultural heritage thesauri to wordnet: two case studies. ACL 2007, page 57, 2007.
[24] C. D. Manning, P. Raghavan, and H. Schütze. Introduction to information retrieval. Cambridge University Press Cambridge, 2008.
[25] C. D. Manning and H. Schütze. Foundations of statistical natural language processing. MIT press, 1999.
[26] P. Mayr and V. Petras. Cross-concordances: terminology mapping and its effectiveness for information retrieval. In World Library and Information Congress: 74th IFLA General Conference and Council. IFLA, August 2008.
[27] I. McIlwaine. The Universal Decimal Classification. UDC Consortium, 2000.
[28] J. S. Mitchell, J. Beall, R. Green, and G. Martin, editors. Dewey Decimal Classification and Relative Index. OCLC, 23 edition, 2011.
[29] K. Pearson. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 50(302):157—175, 1900. http://doi.org/10.1007/978-1-4612-4380-9_1
[30] H. G. Schulte-Albert. Gottfried Wilhelm Leibniz and Library Classification. The Journal of Library History, 6(2):133—152, 1971.
[31] R. Thompson, K. Shafer, and D. Vizine-Goetz. Evaluating Dewey concepts as a knowledge base for automatic subject assignment. In Proceedings of the second ACM international conference on Digital libraries, pages 37—46. ACM, 1997. http://doi.org/10.1145/263690.263790
[32] D. Vizine-Goetz. Popular LCSH with Dewey Numbers: Subject headings for everyone. Journal of library administration, 34(3-4):293—300, 2001. http://doi.org/10.1300/J111v34n03_08
[33] S. Wang, A. Isaac, B. Schopman, S. Schlobach, and L. Van Der Meij. Matching multi-lingual subject vocabularies. In Research and Advanced Technology for Digital Libraries, pages 125—137. Springer, 2009. http://doi.org/10.1007/978-3-642-04346-8_14
[34] A. S. Weigend, E. D. Wiener, and J. O. Pedersen. Exploiting hierarchy in text categorization. Information Retrieval, 1(3):193—216, 1999. http://doi.org/10.1023/A:1009983522080
[35] Y. Yang and J. O. Pedersen. A comparative study on feature selection in text categorization, pages 412—420. Morgan Kaufmann Publishers, 1997.
[36] M. L. Zeng and L. M. Chan. Trends and issues in establishing interoperability among knowledge organization systems. Journal of the American Society for Information Science and Technology, 55(5):377—395, 2003. http://doi.org/10.1002/asi.10387
[37] M. L. Zeng and L. M. Chan. Metadata interoperability and standardizationa study of methodology part II: Achieving interoperability at the record and repository levels. D-Lib Magazine, 12(6), 2006, http://doi.org/10.1045/june2006-zeng.
About the Author
 |
Markus Michael Geipel graduated with distinction from Technische Universität München in Computer Science and earned a doctorate from the Swiss Federal Institute of Technology, Zurich. In 2011 he joined the German National Library where he worked on the German Digital Library (DDB) and created the software architecture of culturegraph.org. Together with Christoph Böhme, he founded the Open Source Project Metafacture/Metamorph to facilitate the processing of bibliographic metadata. Since 2013 Dr. Geipel has worked on software architecture for machine learning and data analytics at Siemens Corporate Technology. His latest open source project is Omniproperties. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |