|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Ana Alice Baptista |
![]()
AbstractAlthough informal communication has always been a part of scholarly communication, its value as an important means for sharing perceptions and knowledge has not always been recognized or properly put to good use. Three add-ons for the DSpace platform have been developed under the "DSpace Dev@University of Minho" project. The next natural step is to further develop and integrate the features of these add-ons into a new cross-repository service that allows knowledge to be transferred across communities in a broader and improved way and to provide better means to access comprehensive information about communication relationships between scholarly entities. Some of the changes that will have to be made to the current features of these add-ons in order to implement such a system have been identified and described in this article. We also present the rationale that supports the vision of a system that accommodates the add-ons developed. Such a system will provide an informal communication layer at the top of the existing network of repositories directly connected to the formal one. In addition, some changes are proposed to the way the Web of Communication is calculated and depicted in order to provide more qualitative information about the communication relationships between scholars. 1. Introduction"It is worth remembering (...) that communication changes have always occurred: it is simply that current changes are particularly rapid and radical". (Meadows, 1997) At the beginning of civilization, communication was essentially oral. The oldest records of written language date from around year 3000 BC (MSN® Encarta®, 2006). Before the invention of the printing press, knowledge was already conveyed in books. However, the access to that knowledge was restricted to a small portion of the world's population, mostly the clergy and nobility. Before Guttenberg, generally accepted as the inventor of the press in the Occident, only about 30,000 manuscripts had been produced in the whole world, ever. In the following 150 years, 1,250,000 additional manuscripts were created and distributed (McGarry, 1984). The invention of the printing press has positively influenced the growth of scholarly communication, having greatly boosted the production of formal documents, which soon became the favored form of communication among scholars. The Association of College and Research Libraries (ACRL) states that "scholarly communication is the system through which research and other scholarly writings are created, evaluated for quality, disseminated to the scholarly community, and preserved for future use. The system includes both formal means of communication, such as publication in peer-reviewed journals, and informal channels, such as electronic listservs." (ACRL, 2003). Informal communication has always played an important role in scholarly communication. "Invisible colleges"1 are examples of this. In this context, restricted groups of scholars share information and ideas at an informal level. These practices are considered fundamental for scientific progress (Merton & Garfield, 1986). In addition, knowledge workers, such as scientists, play the role of both authors and readers in an interchangeable way. During this process, there are several exchanges of information at the informal level that add value to subsequent formal communication: the "information pearls" provided by informal (sometimes casual) discourse. Presently, there are thousands of distribution lists and fora that researchers use to exchange ideas. However, most of these informal interactions are not saved and, even when they are, the information that is exchanged stays hidden, i.e., it is not easy to find these items of information through current search mechanisms2. Another problem is that scholarly communication is not viewed as a whole, i.e., as being composed of both formal and informal communication. Instead, the two elements are treated in completely different and separate ways, as if they could in fact be separated. The truth is they cannot: they are head and tail of the same coin. The solution to this problem is to establish direct relationships between formal and informal communication, in terms of the systems' functionalities and in terms of the documents3,4 that sustain these types of communication. Although there are already many systems establishing some connection between the two types of communication – allowing, for example, comments to be attached to articles – in general, these informal documents can only be accessed internally within an organization or context ( e.g., on a certain Web page), i.e., they are not available globally nor do they have relationships to external documents other than the ones that are established by the links within their bodies. At the same time, the use of what is referred to as social software is gaining momentum. Tools like Connotea,5 unalog,6 Del.icio.us7 and Flickr8 are popular Internet applications whose aim is to establish a connection between some type of formal input (or at least not so transient, e.g., journal articles, Web pages or photos) and some informal ones, such as user-defined tags or user comments. Connotea, unalog and CiteULike,9 have an academic focus (Hammond et al., 2005). Current social software already enables the user to establish a connection between formal and informal documents, this being one of its main virtues. However, it is possible to go even further by: (1) linking several documents at a time; (2) providing richer functionalities for informal communication; (3) increasing the visibility of informal documents on the Web. In this context and under the "DSpace Dev@University of Minho" project, three10 add-ons for the DSpace platform were developed: Controlled Vocabulary (part of the current official version of DSpace), Commenting, and Web of Communication (WoC). The goal of the project that builds upon "DSpace Dev@University of Minho" is to integrate the features of the three add-ons to:
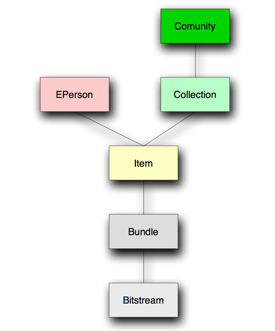
This article starts to describe the "DSpace Dev@University of Minho" project that developed three add-ons for the DSpace platform that support or are somehow related to informal scholarly communication. Then, in section 3, it discusses the next steps to be taken for integrating the features of these add-ons in a way that conforms to the project rationale. Section 4 presents conclusions and describes future work for the project team. 2. The Add-ons Developed under the "Dspace Dev@University of Minho" ProjectThe University of Minho was the first organization in the Portuguese-speaking community (which numbers approximately 200 million speakers12) to translate and implement DSpace13. The University of Minho's institutional repository is called RepositóriUM14 and it has been running since July 2003 (Rodrigues et al., 2004). After an initial implementation period where most efforts were concentrated in creating an effective system setup, the focus shifted to some R&D projects that took DSpace as a development platform. In early 2004, "DSpace Dev@University of Minho",15 a research project whose goal was to develop and implement innovative functionalities that were thought of as important to enhance DSpace usage, was initiated. To support these developments, an additional DSpace repository called Papadocs16 was created. Papadocs stores and gives access to students' assignments and it was used as a test-bed for the components developed under the "DSpace Dev@University of Minho" project. Before proceeding to the detailed description of each add-on developed by the project, we will first describe DSpace system resources and their relationships. Description of DSpace ResourcesIn order to better understand the project add-ons, it is necessary to be aware of the types of resources that accompany DSpace and how they relate to each other. DSpace distinguishes several types of resources that are represented by objects in the database (Tansley et al., 2003). These can be regarded as independent entities containing specific properties (e.g., title, author, date, URL, etc.). A DSpace instance handles the following types of resources:
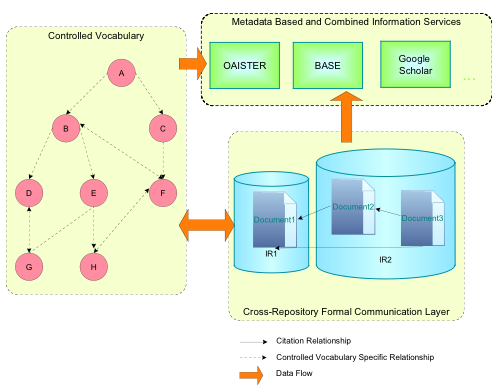
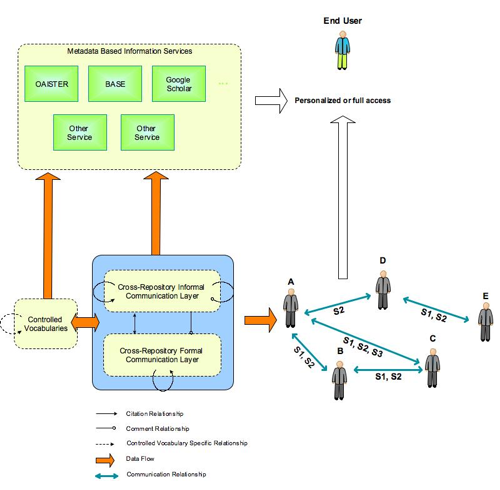
The Controlled Vocabulary Add-onThe main goal of the Controlled Vocabulary add-on was to facilitate and improve resource discovery through the use of controlled vocabularies (Ferreira & Baptista, 2005). These controlled vocabularies were used as sources for values for the subject DC element. These values for subject could then be used to query the system. The use of a common set of keywords to describe and index documents in a cross-repository environment was expected to enhance relevance in search results both at a local and a global level (see Figure 2). Queries on local or centralized metadata services or even combined services ( e.g. OAISTER17, BASE18 or Google Scholar 19) could then be performed in a data-coherent way. Obviously, in a cross-repository environment, these features would only work if the centralized search system provided all users the opportunity to search using the same controlled vocabularies or if some mapping into these vocabularies had been done. The subject-based search functionality on local instances of DSpace is already offered by the add-on. It is worth noting that the Controlled Vocabulary add-on has been integrated into version 1.4 of DSpace.
In order to restrict the problem domain, the project decided to start by using the ACM Computing Classification System (ACM CCS) (see Figure 3). An XML schema was developed from scratch specifically to accommodate the ACM CCS. The resulting XML version for this vocabulary was then submitted to ACM, which adopted it as its official XML version for ACM CCS.20 So far, our XML schema has been used to describe several other controlled vocabularies to be used in the scope of DSpace: the MISQ Keyword Classification Scheme,21 the Norwegian Science Index22 and the Swedish Research Subject Categories.23
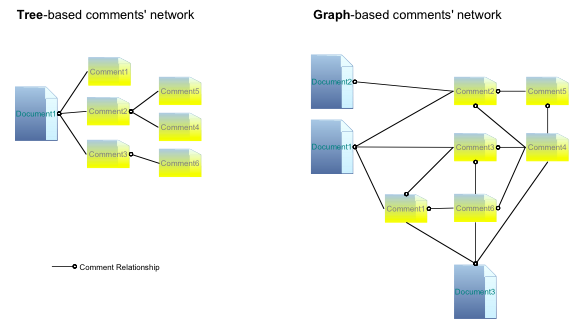
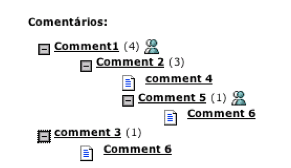
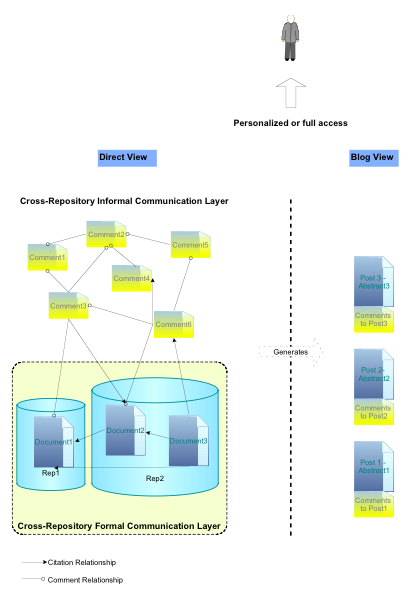
The Commenting Add-onThe main goal of the Commenting add-on was to bring informal communication to DSpace in a way that it would be directly related to formal communication. So far DSpace has not provided any mechanisms to enable its users to carry out any kind of informal communication activities. The Commenting add-on enables users to attach textual messages to DSpace resources. The add-on itself resembles a common discussion forum. However, most fora systems are based on tree structures (i.e., messages are grouped in conversation threads), whilst this add-on provides a graph-based forum structure, meaning that a single comment can simultaneously be attached to several distinct resources (those being items, epersons or other comments). The fact that the comment network is graph-based instead of tree-based (see Figure 4) makes it easy to implement comments that relate two or more resources, independently of their type (not necessarily other comments).
This single feature is of extreme importance, because by attaching a comment to several distinct resources, the comment is in fact relating all those resources at once. This means that the user is able to simultaneously comment on one or more DSpace items (i.e., a formal document) and/or one or more previously inserted comments (i.e., an informal document) (see Figure 5).24
Figure 5 depicts a network of comments that may be presented in a tree-like way as shown in Figure 6. Notice that Comment 6 comments on Comments 3 and 5 simultaneously. However, in the tree-like view the comment has to appear two times: once below Comment 3 and again below Comment 5.
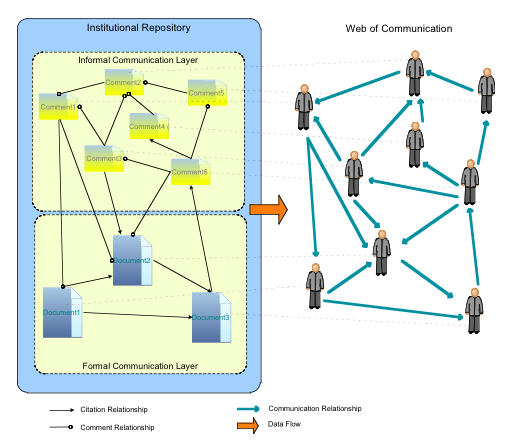
The Web of Communication add-onThe goal of the Web of Communication (WoC) add-on was to provide a way to determine and depict the existing relationships between scholars that would otherwise be invisible. This may provide extremely important value-added services in the context of scholarly communication, since it depicts an approximate view of the relationships between scholars both at the formal and informal level. For instance, the WoC may be used by scholars to identify potential research partners by getting to know who is close to them in the Web of Communication. A Web of Communication is a network of weighted communication relationships between persons. In the case of scholarly communication, these persons are scholars, who, as previously seen, act both as readers and authors. The WoC add-on is based on the assumption that, by having comprehensive records of (both formal and informal) communication between people, communication relationships between them can be inferred and depicted (see Figure 7).
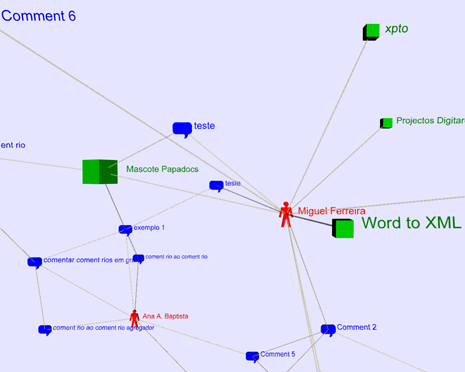
When a comment is attached to one or more documents, invisible links are being created between these documents, the comment, the users who have submitted them and the user that has posted the new comment. All of the resources involved and their invisible relationships are used to create the WoC. Calculating the WoC provides knowledge about how different users interact with each other and with which resources. Users with similar interests share the same parts of the WoC. The WoC is implemented using VRML and allows the user to choose which "thing" he or she wants to have as the center of the network: a person, a formal document or an informal document. From there, it is possible to visualize related persons and documents (see Figure 8 for a screenshot of part of a WoC).
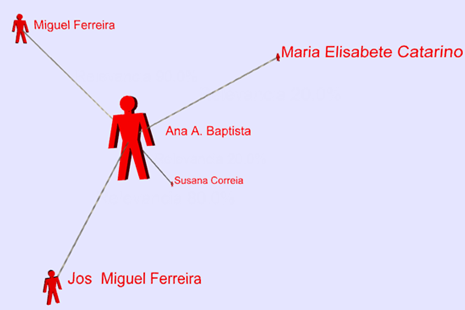
In this version of the WoC, relationships between persons are depicted through the documents on which those relationships are based – it does not depict person-to-person relationships, but person-to-document-to-person relationships. Another version of the WoC add-on produces a graph where document-to-document and document-to-person relationships are collapsed and only person-to-person relationships are exposed. This version depicts much more closely the original idea of the WoC as shown in Figure 9.
The three add-ons described above were developed, implemented in Papadocs and made available to the DSpace community in 2004. They are being used in Papadocs and in other DSpace instances worldwide, and some of the organizations using them are further developing the add-ons or are planning to do so. In this context, and taking into account the ideas that preceded the development of the add-ons, those who are further developing them will have to consider the integration of their features into a whole cross-repository platform-independent system. Section 3 presents the main ideas on why, where and how to change these add-ons. 3. The Next StepsAll the add-ons described above were implemented in the year 2004 on Papadocs as they were being released. This gap of more than two years has made it possible for the team to realize some of the limitations that may hinder the degree to which the goals that led their development were achieved. Next we identify the current main limitations of each of the add-ons and the changes that should be made in order to resolve them. Afterwards, the overall vision of the system that results from the aggregation of the features of the three add-ons will be presented. The Controlled Vocabulary featuresAs explained earlier, an early XML version of the ACM CCS was created as a sub-product of the development of the Controlled Vocabulary add-on. At that time, an unofficial version of the ACM CCS using OWL25 was developed. However, that version was not adopted mainly because the ACM CCS is a simple controlled vocabulary that does not need many of the complex structures of OWL. The XML schema developed subsequently was much simpler, easier to work with and, therefore, easier to disseminate. The main limitations of the Controlled Vocabulary add-on are the following:
The main change that derives from this is
The Commenting featuresThe Commenting add-on was developed to be used inside a repository, i.e., comments could only be attached to other resources within the same repository. However, this is not a real-world solution, because:
If it is important to enable communities to emerge from formal documents through informal documents, then it doesn't make sense to make the service local – it should be global, i.e., it should be accessible from both inside and outside each repository. It should be a cross-repository system. The first change to the Commenting features is the following:
In order to raise the importance of informal documents to a level similar to that of formal ones, the inclusion of metadata values is of major importance. It seems natural, for instance, to use controlled vocabularies to provide values for the subject metadata element. To make things easier for the end user, comments could inherit by default the subjects of the formal documents to which they are attached. This feature would lift informal documents to the level of formal ones in queries, subject-based indexes and other services that use the subject metadata element. Free user tags, such as the ones used in Connotea or Del.icio.us, might be used concomitantly. Some of the aforementioned services also rely very much on an author's identity, e.g., for querying by author. Consequently, information derived from some kind of global authority table could also be added to the resulting system. Recently, a discussion on the American Scientist Open Access Forum and another in the DSpace Tech mailing list addressed this issue.26,27 It seems clear that the community still needs to get involved in further research on this topic, as it is of major interest for all services whose results are built upon authors' identities. In this view, services such as OAISTER, BASE and Google Scholar could include information about informal documents in their query results, if requested. The DC Type metadata element could easily be used to store the document type. Thus, the inclusion of informal document types in the search results could be defined at the query level. On the other hand, most of the time comments are not as interesting as formal documents, and there are probably many comments that are not interesting at all. Search engines should be able to calculate the level of importance of an informal document according to, for instance, the number of other comments or the number of citations derived from it. Therefore, the next change to the Commenting features has to do with metadata:
After more than two years of experience with the Commenting add-on being used in Papadocs, it seems that users have some difficulty commenting on each other's works directly. There isn't any empirical evidence that confirms or denies the assumption that users don't feel comfortable commenting on each other's works, neither in Papadocs nor in any other implementation of the Commenting add-on. Nonetheless, there are not many comments, which raises some doubts as to whether there might be some discomfort in doing it. If this is true, a possible solution could be to use an intermediate service, such as a blog, for commenting. A blog has the advantage of having already acquired the social habit of commenting. Although blog posts are frequently classified as informal communication and blog comments are organized sequentially, some modifications could be introduced (see Figure 10):
Therefore, another change in the Commenting features would be:
Figure 11 depicts what is envisioned for the system that results from the application of all the changes mentioned above.
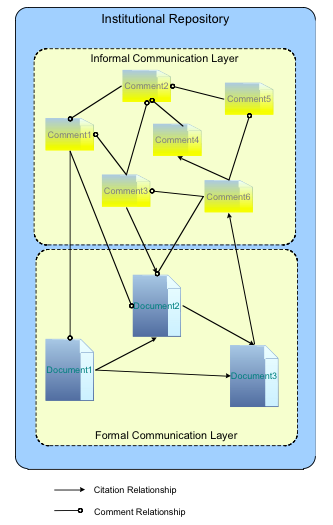
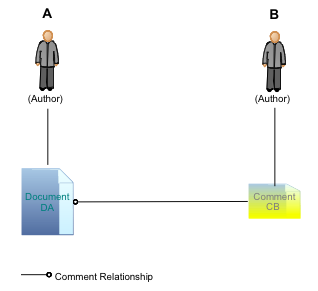
The Web of Communication featuresThe WoC add-on generates a network that is based on information derived from commenting relationships that are present both in formal and informal documents. It relates authors (both formal and informal document authors) through the commenting relationships present on their authored documents. For instance, if author A has written a formal document DA, and author B has written a comment CB on document DA, then these two authors are depicted as related through documents DA and CB (see Figure 12 and Figure 13).
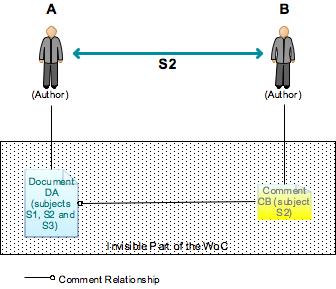
Much more interesting than knowing which documents sustain a relationship established between two persons is knowing which subjects support that relationship. The WoC resulting picture does not need to show the supporting documents at first – it needs only to show the subject(s) that underly that relationship (see Figure 13). If the user should want further information, it could be possible then to show all the underlying structures.
At this stage, another change is the following:
In the current add-on, all communication relationships between persons are depicted. Once relationships are depicted in a person-to-document-to-person basis, if there were 300 documents relating person A and person B, 300 relationships would be depicted. However, much more important than showing the documents through which people relate to each other, is to weight them in order to calculate the tightness of the relationship. Relationships could have different weights according to the type of documents that support them or the type of the relationships themselves (citation, comment, co-authorship, download, etc.). A measure of the tightness of a relationship between two persons could result from the calculation of the relative weights of these relationships. This measure of tightness could then be depicted some way so that its relative importance could easily be grasped from the WoC.
The current version of the add-on still does not include information derived from citation relationships. This kind of information is fundamental for at least understanding formal documents' relationships. Consequently, handling this information is vital for establishing a reliable WoC. Thus, another change will be the following:
Filters could be applied in order to depict only the relationships above or below some measure of tightness. Other kinds of filters (e.g., nature of the relationship) could also be developed. Another change therefore would be:
The current add-on does not show information about the direction of the communication, e.g., if it is in both directions (bidirectional) or only in one direction (unidirectional). When a given author is cited or commented on by another, but there is no record of communication in the opposite direction, then this relationship is unidirectional. In cases in which there are records of communication in both directions, the relationship is bidirectional. It is important to conveniently depict this kind of information in the WoC so that the direction of the communication is easily grasped. As such, another change is needed:
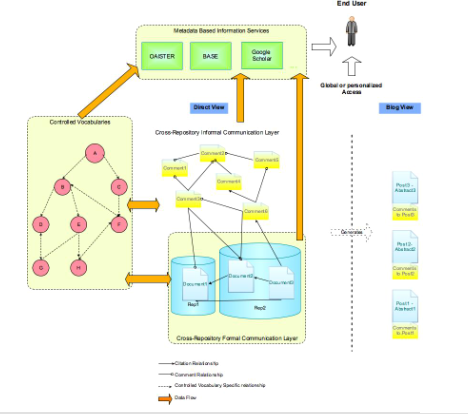
4. Conclusions and Future WorkThe Global PictureFigure 14 shows the global picture of the integrated system. In order to assure it is readable, some simplifications have been made: some parts that were explained before have been condensed; and the part of the blog-like view has not been included (it is just an example of how to provide a better environment for the user to feel comfortable in commenting on peers' work: the underlying structure is the same).
Informal documents (comments, in this case) may be used as a way to store informal interactions, and if they are directly related to formal ones, they are more easily found, used and re-used. In the envisioned system, the connections between the formal and informal layers are provided either by comment or by citation relationships. Comment relationships have the advantages of (1) providing the ability to relate two or more documents using a single relationship; (2) providing a human-readable text (the comment itself) that gives meaning to those relationships and (3) having that text (comment) available directly from the referred documents.28 Once informal documents are indexed the same way as formal ones (at least in what concerns subject and author), they will be able to be returned as query results by metadata-based and combined search engines. Filters might be applied to these systems in order to restrict the type of document or its relative importance according to some criterion. At the same time, in order to make people more comfortable with commenting on their peers' work, other views of the system might be provided. For example, the blog look and feel might be used. Information provided to the end user of such a system may be treated in several ways in order to be useful: it may be filtered, condensed, expanded, etc., according to user guidelines that can be stored in his or her profile. If the system is cross-repository and platform independent, i.e., if it is able to handle concomitantly documents stored in different repositories independently of the technology used by those repositories, then the WoC that is generated will show relationships between scholars at a global level, independently of their affiliation and/or any geographically imposed limitations: what is really important is the communication relationships between scholars. That is why WoC stands for Web of Communication. Future WorkThe integration of the features of these add-ons is a natural evolutionary step that comes from earlier positions regarding this matter. Together with these positions, there are others that might be added to a final architecture resulting both in a more interesting informal communication layer and in a better WoC. However, some research work on the current state of the art on collaborative systems and social software is necessary. There are some features that have already proved to make sense in such a system, but others will have to be derived from current implementations or from new approaches. Social Network Analysis and other theories that might support the WoC will be studied deeply. It would also be interesting to make some longitudinal studies to determine whether knowledge exchange between communities would result from the addition of this informal communication layer. A project following the "DSpace Dev@University of Minho" project is under activation, and partnerships with research teams in other national and international institutions are under way. AcknowledgementsThe authors wish to acknowledge John W. T. Smith (The Templeman Library, University of Kent, England) and Johannes Van Reenen (The University of New Mexico, USA) for their detailed comments on an early draft of this article. Notes1. Invisible Colleges designate "the informal collectives of closely interacting scientists, generally limited to a size that can be handled by interpersonal relationships. (...) [They are] significant social and cognitive formations that advance the research fronts of science." (Merton & Garfield, 1986) 2. Search engines, such as Google, provide thousands of results per query. These results are ranked according to several criteria, including the number of times the items have been accessed. In general, informal documents are not among those which appear in the first result sheets and, therefore, become more and more invisible (because the tendency is for the items which are accessed more often to be accessed even more often). 3. In the context of this article, the word "document" is used in its broadest sense, "to denote all enduring communicative records" because "documents come to us not as isolated artifacts but as instances of recognizable social types or genres – e.g., as novels, packing receipts, shopping lists, journal articles, and so on." (Levy & Marshall, 1994) 4. For simplicity, the expression "formal document" will be used from now on to refer to "formal communication document"; similarly the expression "informal document" will be used from now on to refer to "informal communication document". 5. See <http://www.connotea.org/>. 6. See <http://unalog.com/>. 7. See <http://del.icio.us/>. 8. See <http://www.flickr.com/>. 9. See <http://www.citeulike.org/>. 10. In fact, the project comprised the development of a fourth add-on, the Recommendation add-on. However, as the important part of its functionality was derived from the WoC add-on, its description will not be included in this article. 11. Don Swanson "has called information that is inferable from what has already been published undiscovered public knowledge, that is, knowledge that exists implicitly in the literature (in terms of potential relationships between existing items) and yet is not known by any one person (intelligence)" (Spasser, 1997). 12. According to the CIA factbook, Portuguese is the 5th most spoken language in the world. 13. DSpace is a "digital repository system that captures, stores, indexes, preserves, and redistributes an organization's research data." (DSpace Federation, 2006). See <http://www.dspace.org/> for further information. 14. See <http://repositorium.sdum.uminho.pt/>. 15. See <http://dspace-dev.dsi.uminho.pt/>. 16. See <http://papadocs.dsi.uminho.pt>. 17. See <http://www.oaister.org>. 18. See <http://base.ub.uni-bielefeld.de/index.html>. 19. See <http://scholar.google.com>. 20. See <http://www.acm.org/class/1998/acmccs98-1.2.3.xml> for the XML version of the ACM CCS. 21. See <http://www.misq.org/roadmap/codes.html>. 22. See <http://gammel.uhr.no/utvalg/forskning/dokumenter/forskdokNorskvitdisinnst.htm>. 23. See <http://www.ub.uu.se/epub/categories/>. 24. Concomitantly, the user may comment one or more epersons. Although this is very interesting, it falls out of the scope of this article and won't be discussed here. 25. See <http://www.w3.org/2004/OWL/>.
26. See <http://listserver.sigmaxi.org/sc/wa.exe?A2=ind06&L=american-scientist-open-access-forum&D= 27. Notice that the link in footnote 26 materializes nothing more than a formal document (this one) referencing informal ones (such as posts in discussion fora). 28. Forward references allow the referring documents to be available from the referred ones as well. ReferencesACRL, ACRL Scholarly Communications Committee (2003, June). Principles and Strategies for the Reform of Scholarly Communication: Scholarly Communication Defined. American Library Association. Available at <http://www.ala.org/ala/acrl/acrlpubs/whitepapers/principlesstrategies.htm>. (Accessed 18 October, 2006.) DSpace Federation (2006). Introducing DSpace. Available at <http://dspace.org/introduction/index.html>. (Accessed 4 November, 2006.) Ferreira, M.; Baptista, A. A. (2005). The use of Taxonomies as a way to achieve Interoperability and improved Resource Discovery in DSpace-based Repositories. Proceedings of the conference "XATA 2005: XML: Aplicações e Tecnologias Associadas", Vila Verde, Braga, Portugal. Available at <http://hdl.handle.net/1822/873>. (Accessed 4 November, 2006.) Hammond, Hannay, T.; Lund, B.; Scott, J. (2005, April). Social Bookmarking Tools (I). D-Lib Magazine, 11 ( 4). Available at Available at <doi:10.1045/april2005-hammond>. (Accessed 4 November, 2006.) Levy, D. M.; Marshall, C. C. (1994, June). Washington's White Horse? A Look at Assumptions Underlying Digital Libraries. Proceedings of the "First Annual Conference on the Theory and Practice of Digital Libraries", Texas, USA. Available at <http://csdl.tamu.edu/DL94/paper/levy.html>. (Accessed 4 November, 2006.) McGarry, K. J. (1984). Da Documentação à Informação: Um Contexto Em Evolução. Lisboa, Portugal.: Editorial Presença, Lda. Meadows, J. (1997, June). Changing Patterns of Communication and Electronic Publishing. Proceedings of the "Scholarly Communication in Focus: 18th IATUL Conference", Trondheim, Norway. Available at <http://www.iatul.org/conference/proceedings/vol07/papers/full/meadpap.html>. (Accessed 4 November, 2006.) Merton, R.K.; Garfield, E. Little Science, Big Science ... and Beyond by Derek J. de Solla Price: Foreword. Available at <http://www.garfield.library.upenn.edu/lilscibi.html>. (Accessed 4 November, 2006.) MSN®, Encarta® (2006). Communication. Available at <http://encarta.msn.com/encyclopedia_761564117_2/Communication.html>. (Accessed 8 November, 2006.) Rodrigues, E.; Baptista, A. A.; Ramos, I.; Souza; M.F.S. (2004, June). RepositóriUM - Implementing DSpace in Portuguese: Lessons for the future and Research Pathways. Proceedings of the "Elpub2004 - ICCC 8th International Conference on Electronic Publishing", Brasília, Brazil. Available at <http://hdl.handle.net/1822/603>. (Accessed 4 November, 2006.) Spasser, M. A. (1997). The Enacted Fate of Undiscovered Public Knowledge. Journal of the American Society for Information Science, 48(8), 707-717, New York - USA: John Wiley & Sons, Inc. Tansley, R.; Bass, M.; Branschofsky, M.; McClellan, G.; Stuve, D. (2003). DSpace System Documentation. Available at <http://www.dspace.org/technology/system-docs/>. (Accessed in 2004.) Copyright © 2007 Ana Alice Baptista and Miguel Ferreira |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2007-baptista
|

{kind=link}