|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2016
Volume 22, Number 1/2
Data Citation Services in the High-Energy Physics Community
Patricia Herterich
CERN and Humboldt-Universität zu Berlin
patricia.herterich@cern.ch
Sünje Dallmeier-Tiessen
CERN
sunje.dallmeier-tiessen@cern.ch
DOI: 10.1045/january2016-herterich
Abstract
A paradigm change in scholarly communication is underway. Supporting Open Science, an effort to make scientific research data accessible to all interested parties by openly publishing research and encouraging others to do the same thereby making it easier to communicate scientific knowledge, is a part of the change that has become increasingly important for (digital) libraries. Digital libraries are able to play a significant role in enabling Open Science by facilitating data sharing, discovery and re-use. Because data citation is often mentioned as one incentive for data sharing, enabling data citation is a crucial feature of research data services. In this article we present a case study of data citation services for the High-Energy Physics (HEP) community using digital library technology. Our example shows how the concept of data citation is implemented for the complete research workflow, covering data production, publishing, citation and tracking of data reuse. We also describe challenges faced and distil lessons learnt for infrastructure providers and scholarly communication stakeholders across disciplines.
1 Introduction
With the advent of digital infrastructures and services, there is a great potential to improve scholarly communication on a large scale. Open Science, an effort to make scientific research data accessible to all and thereby making it easier to communicate scientific knowledge, is increasingly seen as the way science should be done by funders, policy makers and society. In addition to making text publications Open Access, the Open Science paradigm embraces the sharing of the whole research workflow, including making code, research data and documentation available.
Despite funding pressure (e.g. National Science Foundation, (n.d.); Science & Technology Facilities Council, (n.d.)), publisher policies (e.g. Bloom, Ganley & Winkler, 2014) and emergent services in many disciplines (see Re3data.org for an extensive list of data repositories), researchers have not seemed particularly eager to explore new opportunities and have hesitated to embrace Open Access and Open Data practices for a long time. (Dallmeier-Tiessen, et al., 2011; Tenopir, et al., 2011) Of course, there were some ground breaking examples such as GenBank (Benson, et al.; 2013), but despite the impact digital services have had on our private lives, the changes in the scientific community have happened on a much smaller scale and at a much slower pace. Researchers are in need of greater incentives to help them move beyond the traditional path of publishing final results as text articles and move instead towards Open Science. (Dallmeier-Tiessen, 2014; Tenopir, et al., 2011)
In several studies, data citation emerged as an opportunity to address these barriers and incentivise Open Science. (Fecher, Friesike & Hebing, 2015; Kratz & Strasser, 2015; Van den Eynden & Bishop, 2014) Data citation practices follow the traditional approach of referencing published works (Altman & Crosas, 2013), but these practices are applied to the research materials supporting a paper (e.g. underlying data sets, used software, etc.), which are now published openly. Data citation offers researchers a well-established way to provide references, but moreover and potentially more importantly, to receive credit for their own shared materials.
In this article we present the results of a case study investigating the need, impact and solutions for data citation in one discipline, the High-Energy Physics (HEP) community. This is the first community to implement the concept of data citation through the complete research workflow covering data production, data publishing, citation and reuse tracking. We distil lessons learnt in HEP for digital libraries (and other infrastructure providers and scholarly communication stakeholders) across disciplines and conclude with our future plans and challenges on the way ahead.
Research outputs relevant to the HEP community are datasets of various forms and sizes, as well as analysis code, software and technical environments needed to process the data, or documentation of the research workflow in the form of, e.g., digital lab books. For reasons of simplification, these are all defined as data in this article unless explicitly mentioned otherwise. Following standards like the FORCE11 principles (FORCE11, 2014), these types of material are thus also covered by the term "data citation".
2 The High-Energy Physics community
2.1 Research data and data sharing in the HEP community
As the main users of arXiv, the High-Energy Physics (HEP) community has a tradition of publishing its papers in Open Access. Interestingly, that tradition is not automatically reflected in its track record of participation in other Open Science actions, like sharing research data openly. This could be explained by looking at the specifics of the HEP community for further insights.
The community can be divided into theorists and experimentalists. The former work independently or in small groups, exploring physics questions and generating theories, while the latter form big collaborations to build experiments, produce and analyse data. Examples of these collaborations are ATLAS (A Toroidal LHC ApparatuS), which is a particle physics experiment at the Large Hadron Collider (LHC) at CERN searching for new discoveries in the head-on collisions of protons of extraordinarily high-energy, or CMS (Compact Muon Solenoid), whose particle detector is designed to detect a wide range of particles and phenomena produced in the LHC's high-energy proton-proton and heavy-ion collisions. These collaborations consist of more than 3,000 scientists, engineers, technicians and students from roughly 180 institutes and universities from about 40 countries each.
This setup does not inherently anticipate data exchanges across the collaborations, but provides exclusive access to those who contributed to the experiment. Data shared outside the collaboration requires extra effort and processing to be re-usable and thus has been limited to specific use cases in the past (as it lacked incentives).
Experimental data in HEP is usually categorised following the four levels of research data defined by the Study Group for Data Preservation and Long Term Analysis in High-Energy Physics (DPHEP Study Group, 2009), which give an abstract overview of the data created through all the processing steps from the detector to the publication (see Figure 1).
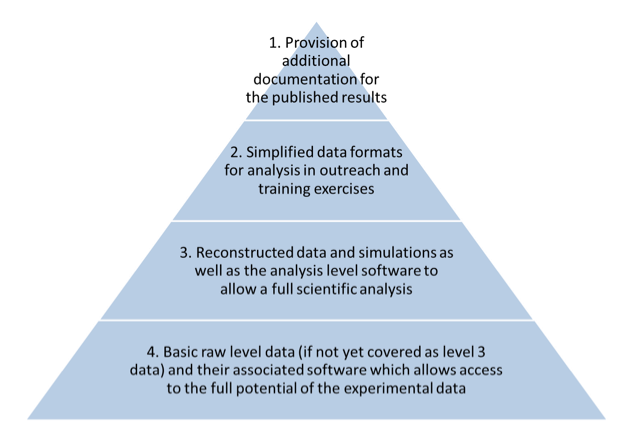
Figure 1: Data pyramid in HEP showing the 4 levels of experimental data.
The bottom of the pyramid comprises raw data as they come out of the detector (Level 4). These data and the associated software provide the full processing potential but are not used for any physics analysis by the experimentalists. Level 3 data covers reconstructed data as well as Monte Carlo simulations which together with analysis level software allow the scientific analysis of the events captured by the detector. Level 3 data, simplified by analysis code, results in simplified data formats that constitute Level 2 data. These datasets are sometimes shared for educational outreach and training exercises. In a further processing step, Level 2 data is prepared for publication. The resulting Level 1 data are visualised in the final paper.
In addition to the data covered in the pyramid, experiments produce e.g. likelihood estimations which are highly processed data but not related to any publication. In some cases, several collaborations combine their data to smooth out statistical errors. Furthermore, the theory community also produces data not covered by the pyramid, such as code embodying a mathematical model. These data are usually linked to a publication.
Inspired by the funder requirements for data management plans, the CMS collaboration was the first of the four experiments at the LHC that discussed data management and sharing. In 2012, CMS developed its data policy (CMS Collaboration, 2012) that commits the collaboration to making their data (Level 2 and 3 as defined by the pyramid in Figure 1) gradually accessible to the public after an embargo period of three years. The other experiments took similar steps shortly afterwards (ALICE Collaboration, 2013; ATLAS Collaboration, 2014; LHCb Collaboration, 2013). All of the experiments' policies state that data will be released under a CC0 waiver, but should be cited by using the persistent identifier assigned upon release.
2.2 Data discovery and citation in HEP so far
The data being shared so far cover different stages of the research workflow, from the discussion of results before publication to supplementary material to the final paper. So far there are only a few standardised ways and established community platforms for publishing data openly, all of which cover level 1 data or additional data not covered by the pyramid (such as the likelihood estimates mentioned before).
- Website of the experiment and wiki-style pages to share small datasets internally: Data are provided in the context of internal discussions before they are published in papers. In most cases, these pages are private and not accessible to non-members of the organization. See Figure 2.

Figure 2: Example of a citation of a collaboration's "twiki-page". Taken from Schenke & Venugopalan (2014).
- HEPData (Buckley & Whalley, 2010): This community platform preserves and provides access to supplementary data from about 8,000 published papers. These datasets usually contain raw numbers behind tables and plots. See Figure 3.

Figure 3: Example of a citation of data deposited in HEPData. Taken from Khachatryan, et al. (2010).
- Pages of physics institutes and/or individual researcher's web sites: These make supplementary data or software available in an independent way. They are usually referenced with a URL only. See Figure 4.
Figure 4: Example of data citations of data available on an institutional homepage. Taken from Zapp (2014).
If theorists, the main consumers, reuse these datasets, they cite them in their papers following various approaches, usually just by adding a URL in the reference list, as these data do not have Digital Object Identifiers (DOIs) assigned and the URL seems to be the only way to directly refer to them. These data citations could be extracted through text mining of bibliographic databases, but the accuracy of the results and matching them to the correct data sets in a database is challenging (Mathiak & Boland, 2015; Meyer, 2008). Thus, citation metrics cannot be applied, linking data to the original source or the creator is impossible, and the reuse and impact of these datasets is hardly visible. Overall, this scenario results in a discoverability challenge, as there are no centralised tools for theorists to find datasets to compare their theories to.
2.3 Digital library services for the HEP community
Two services for the HEP community play a major role in addressing the issue of data discoverability and citation: INSPIRE-HEP and the CERN Open Data Portal. They are explained in more detail here.
INSPIRE-HEP (hereafter referred to as INSPIRE) serves as a central aggregator and discoverability tool for research materials in HEP, mainly literature, but it also covers conferences and job offers from the entire global HEP community. It is based on the Invenio open source digital library software and is run by a consortium of five research institutions: CERN, DESY in Germany, Fermilab and SLAC in the U.S., and IHEP in China. INSPIRE's content is enriched by specialists' curation and bibliometric analysis. Following the requests from its user community, it recently expanded its scope to research data. INSPIRE now connects to data resources such as DataVerse and Figshare and indexes the community data repository HEPData since 2012 (INSPIRE blog, 2012). To strengthen this collaboration, in 2015 HEPData became even more tightly integrated with INSPIRE to provide a centralised service to the community that links data, publications and other research output.
On top of the research materials that are discoverable, INSPIRE adds an additional author and contributor focused layer, which shows profile pages with the authors' publication and citation records. Citation counts to papers are one of the most popular features of INSPIRE. Currently, the numbers are based on text-mining and manual bibliographic curation of the papers in the database. Thus, they might differ from other sources such as Web of Science or Google Scholar. INSPIRE will expand the citation counts to research data and in doing so become one of the first providers of a data citation count. The author pages are also fully integrated with ORCID, the non-profit organization providing a unique and persistent identifier for researchers, importing and exporting publication information. This workflow will soon be extended to export other types of works such as data and software to support the propagation of information across systems.
In 2014, the CERN Open Data Portal was developed as the repository to host Open Access Level 2 and 3 data from the LHC experiments. The portal is run by a close collaboration of physicists from the community, and the Information Technology developers and the data curation specialists at CERN. It was launched in November 2014 (CERN, 2014) and as of October 2015, it provides access to 27 TB of data from the CMS experiment as well as examples of code to analyse these data and the datasets resulting from this analysis. In addition to the complex Level 3 data, the CERN Open Data Portal also provides simplified data examples that can be used for educational purposes from all four LHC experiments. All items in the portal are minted with a DOI to facilitate data citation and tracking.
3 Supporting data publishing and citation in practice
The analysis in Section 2 showed that supporting data citation and engaging researchers in data citation practices is currently one of the biggest challenges for the emerging Open Science practices. Incentives are needed to support and engage individuals to share their code and data. The design and consolidation of new workflows should be embedded into the established community services and research practices. Establishing data citation from the very beginning enables easy sharing, while offering and building trust in data services. Thus, keeping track of data reuse and providing credit for sharing are being established as prominent features for any community platform. INSPIRE, as the central scholarly information platform in HEP, is the core example. It has been designing its services following interdisciplinary standard recommendations whenever possible. This section presents some characteristic examples.
Use case 1: ATLAS likelihood data
The first additional datasets to be released on INSPIRE (in addition to HEPData) were the so called "Higgs datasets" (ATLAS Collaboration, 2013, see Figure 5). These three datasets represent the likelihood functions that support the discovery paper of the Higgs boson and were added manually to INSPIRE. Because they were published to be re-used immediately, the main reason for making them available through INSPIRE (and not depositing them in the community repository HEPData) was that INSPIRE assigned DOIs. Within days, they received their first citations and INSPIRE tracked them, providing links to the publications reusing the data and their author profiles.
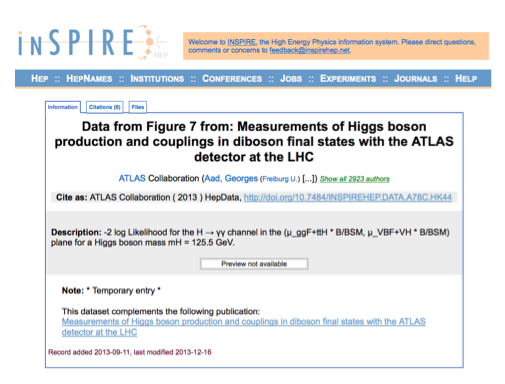
Figure 5: The "Higgs data"on INSPIRE with its tailored citation recommendation and the citation count as of January 29, 2015 (ATLAS Collaboration, 2013).
Use case 2: Theory data
The impact of publishing the ATLAS likelihood datasets was notable within the entire community. Researchers demanded a dedicated workflow to submit data and to assign a DOI to their works. This demand was initially driven by the theory community, as there was no service or platform to publish their material (unlike HEPData which covers experimental data). Following these requests, INSPIRE integrated a submission form to allow researchers to deposit their datasets, which also provides DOI minting upon request. Interestingly, the submissions are often theory data in the form of code snippets (as seen for example in the dataset list below in Figure 7) or algorithms, and many of them have already received citations. This example illustrates how some groups in the community are eager to share code and data but require support and infrastructure to develop these publishing procedures.
Use case 3: Code from GitHub
To address the demand to share software through the traditional means of scholarly communication, as a citable object with accompanying metadata, but using well established tools in the open environment, a workflow was set up to integrate GitHub (Figure 6). GitHub is a widely used repository service for software development with distributed revision control and source code management. The workflow is based on the connection between GitHub and Zenodo, an open preservation and sharing platform for the long-tail of science based on the Invenio software and hosted at CERN. Zenodo enables researchers to easily share and preserve any research outputs in any size, any format and from any science. A snapshot of the code is taken from GitHub upon release and preserved in Zenodo, receiving a DOI there. This persistent identifier along with a standard protocol for harvesting, allows INSPIRE to integrate the content and link the resource to its authors, related publications, etc. As previously mentioned, the new data citation metrics will build upon this information.
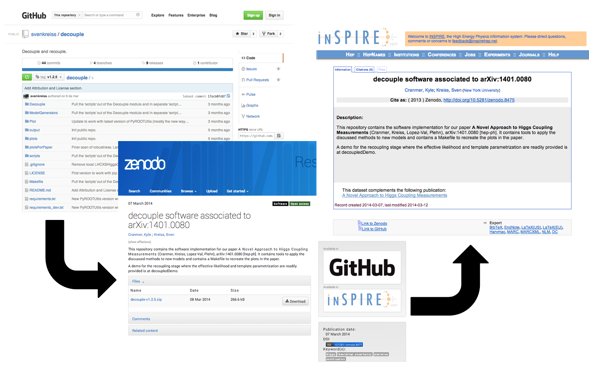
Figure 6: Illustration of the GitHub-Zenodo-INSPIRE code integration.
The developments described that facilitate discovery, reuse and citation of high-level data in HEP show that a collaborative effort of service providers and researchers is essential. It requires a significant adjustment of services and community practices that can only be tackled with a complementary approach to foster adoption.
Use case 4: LHC primary data (public release)
Unlike highly processed data from Levels 1 and 2 which are available on INSPIRE or HEPData, Level 3 data (Figure 1) are too complex in size and metadata for any of the existing public community platforms to host and serve them directly/openly. To the members of the collaborations they are currently accessible through the Worldwide LHC Computing Grid. Thus, the first release of CMS Collaboration data to the public after the embargo period posed a challenge to the existing service providers.
For this CMS data release in 2014, the CERN Open Data Portal was developed as the public access point to Level 2 and 3 data from the LHC experiments. Using CERN's open source digital library software Invenio, this new service was successfully created in a close collaboration between the researchers, developers and data curation specialists at CERN. In addition to providing access to so called primary datasets (Level 3) from the CMS experiment, it hosts examples of code to analyse these data (following the same workflow described above for Zenodo, making the code citable by storing a snapshot from GitHub and assigning it a DOI) and datasets deriving from such an analysis. Furthermore, all LHC collaborations make datasets tailored to educational uses available on the portal.
Virtual machines play a key role in software preservation (Blomer, et al., 2014). In order to provide the proper environment to run the analyses and explore the data, the CERN Open Data Portal offers pre-set virtual machines with correct versions of the software and libraries to guarantee complete compatibility. This infrastructure ensures and supports reuse in the longer term.
Following the data policies of the experiments, the datasets and software examples available in the CERN Open Data Portal have DOIs assigned and each record in the portal shows a citation recommendation similar to the one in INSPIRE (Figure 5). Export to bibliographic services such as BibTeX or EndNote is currently not possible, but it will be implemented in the future to further facilitate data citation.
In contrast to the data accessible through INSPIRE, the user group of the CERN Open Data Portal is less well defined. Many researchers from the collaboration have already had access to these data and have already used them for their research and publications prior to the data's deposit in the CERN Open Data Portal. Thus, it is assumed that the data will be used mostly outside the collaboration, and in particular outside the HEP community, which makes it less simple to predict who will reuse these data and how and where the impact can be tracked. Reuse of the data inside the HEP community will be tracked by INSPIRE using the DOIs, as described in the previous workflows. Tracking reuse outside the HEP community poses an additional challenge for the future. However, interdisciplinary reuse is possible, given the large public interest in the release of the portal.
Currently, new applications of the data or the software are also included in the CERN Open Data Portal if the creators actively notify the support team of their work and scientific contribution. Furthermore, the LHC collaborations will regularly release new datasets as their embargo periods come to an end.
4 Open challenges
The first services addressing research data sharing and data citation in HEP are in place. There are still open challenges, though, that need to be addressed to improve these services.
For example, INSPIRE is stretched to its limit when it comes to several versions of one dataset. There is no straightforward way to handle several versions of a dataset in the system (see list of datasets on the author page in Figure 7). Instead, each version of a dataset is a record on its own, and links to previous, later and current versions of the same dataset have to be created manually. Versioning of the dataset is indicated in the DOI name, as the DOI for a dataset stays the same and is versioned by adding e.g. ".2" for the second version.
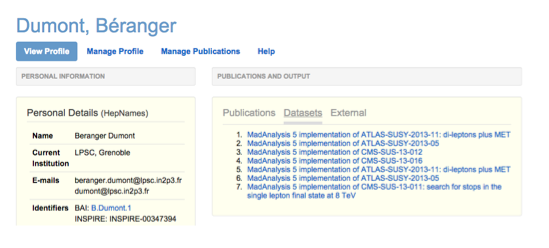
Figure 7: Datasets as part of an author profile on INSPIRE.
A further feature to improve is the dissemination of correct reference/citation information. INSPIRE is currently showing separate citation recommendations for data ("Cite as" in Figure 5 following the FORCE11 principles) and reaching out to its community to establish these recommendations as the standard approach. However, it is necessary to reflect the new data workflows in the export options and external systems. Community members do not copy and paste the written citation recommendations, but mostly rely on tools like BibTeX which do not yet do an adequate job of supporting the citation of research outputs as distinct entities. In order to foster adoption of data citation in the community, it will be important to reflect Open Science practices in reference management systems (Fenner, 2015).
As highlighted earlier, an open challenge for data reuse and data citation in HEP is the lack of data discoverability. To improve the discoverability of research data within the community, data models for the CERN Open Data Portal and INSPIRE will be refined and made compatible. In addition, the HEPData repository will support new functionalities such as DOI assignment and integrate with the rest of the services. Furthermore, INSPIRE, as the content aggregator for the community, is developing new tools to search and connect data with publications and authors, as well as exposing this to external services via APIs.
5 Conclusions
Within HEP, emerging Open Science practices and service developments are tightly knit. CERN builds frameworks to enable the community to do science, while complying with emerging standards at the same time. The case study in this paper underlines that, as studies suggest, being cited is a real driver behind sharing data or code publicly and getting a DOI assigned. We have also seen that researchers are more likely to share their own research outputs if they have already profited from data shared by others (see use case 2).
A crucial lesson learned is that developing the services closely with the community is essential to embed new workflows in established systems and to guide the community towards Open Science practices and the use of standards. However, there is still a long road ahead, considering all the complex research materials that are available in HEP. Data publication, discovery, and citation can still be better integrated into current research workflows. Thus, it has been decided to expand the building blocks presented here and to support earlier research phases with tailored solutions. An additional data management service is currently under development which will preserve early stage (user generated) data products and related materials. The service will be interoperable with the already existing community platforms CERN Open Data Portal and INSPIRE, allowing easy publication of research outputs in these services, which will then assign a persistent identifier.
When it comes to the development of data citation metrics, more debate within the HEP community and collaboration across all disciplines is needed. General solutions currently exists, such as the Thomson Reuters Data Citation Index (Force & Robinson, 2014) and PLOS Article Level Metrics and the dataset level metrics (Lin, et al., 2014), but there are still further points for discussion. Data citation metrics need to be adjusted to account for discipline-specific data sharing customs (e.g. if data are shared in collections or as many single datasets, how granularly DOIs are assigned). However, the first step is to make data citation trackable, as the use cases presented in this article show. This is being studied and prototyped as part of the THOR project. THOR (Technical and Human Infrastructure for Open Research) is a European Commission (Horizon 2020) funded project aimed at improving the interoperability of persistent identifiers through collaborations with identifier-granting organizations and developers of disciplinary repositories. As one of the project partners, CERN will investigate how the services for the HEP community introduced in this paper can be improved, and prototypes for enhanced research data services will be developed.
Acknowledgements
The authors would like to thank Laura Rueda Garcia and the teams behind INSPIRE-HEP and the CERN Open Data Portal for their contribution to the services. The described work would not be possible without Annette Holtkamp, Samuele Kaplun, Jan Åge Lavik, Javier Martin Montull, Tibor Simko and Pamfilos Fokianos. Furthermore, we thank Salvatore Mele, Artemis Lavasa, Lars Holm Nielsen, Tim Smith and Robin Dasler for their valuable feedback during the writing process. Patricia Herterich's work on this paper was funded by the Wolfgang Gentner Programme of the Federal Ministry of Education and Research.
References
| [1] | National Science Foundation (n.d.). NSF Data Management Plan Requirements. |
| [2] | Science & Technology Facilities Council (n.d.). STFC Scientific Data Policy. |
| [3] | Bloom T., Ganley E., & Winker M. (2014). Data Access for the Open Access Literature: PLOS's Data Policy. PLoS Biology 12(2): e1001797. http://doi.org/10.1371/journal.pbio.1001797 |
| [4] | Dallmeier-Tiessen, S., Darby, R., Goerner, B., Hyppoelae, J., Igo-Kemenes, P., et al. (2011). Highlights from the SOAP project survey. What scientists think about open access publishing. arXiv preprint. |
| [5] | Tenopir C., Allard S., Douglass K., Aydinoglu A.U., Wu L., et al. (2011). Data Sharing by Scientists: Practices and Perceptions. PLoS ONE 6(6): e21101. http://doi.org/10.1371/journal.pone.0021101 |
| [6] | Benson, D. A., Cavanaugh, M., Clark, K., Karsch-Mizrachi, I., Lipman, D. J., Ostell, J., & Sayers, E. W. (2013). GenBank. Nucleic Acids Research, 41(D1): D36-D42. http://doi.org/10.1093/nar/gks1195 |
| [7] | Dallmeier-Tiessen, S. (2014). Drivers and barriers in digital scholarly communication (Doctoral dissertation, Humboldt-Universität zu Berlin, Philosophische Fakultät I). |
| [8] | Fecher B., Friesike S., & Hebing M. (2015). What Drives Academic Data Sharing? PLoS ONE 10(2): e0118053. http://doi.org/10.1371/journal.pone.0118053 |
| [9] | Kratz, J. E., & Strasser, C. (2015). Making data count. Scientific Data, 2. http://doi.org/10.1038/sdata.2015.39 |
| [10] | Van den Eynden, V., & Bishop, L. (2014). Sowing the seed: Incentives and motivations for sharing research data, a researcher's perspective. A Knowledge Exchange Report. |
| [11] | Altman, M., & Crosas, M. (2013). The Evolution of Data Citation: From Principles to Implementation. IASSIST Quarterly, 37, 62. |
| [12] | FORCE11 (2014). Joint declaration of data citation principles. |
| [13] | DPHEP Study Group. (2009). Data Preservation in High Energy Physics. arXiv preprint. |
| [14] | CMS collaboration (2012). CMS data preservation, re-use and open access policy. CERN Open Data Portal. http://doi.org/10.7483/OPENDATA.CMS.UDBF.JKR9 |
| [15] | ALICE collaboration (2013). ALICE data preservation strategy. CERN Open Data Portal. http://doi.org/10.7483/OPENDATA.ALICE.54NE.X2EA |
| [16] | ATLAS collaboration (2014). ATLAS Data Access Policy. CERN Open Data Portal. http://doi.org/10.7483/OPENDATA.ATLAS.T9YR.Y7MZ |
| [17] | LHCb collaboration (2013). LHCb External Data Access Policy. CERN Open Data Portal. http://doi.org/10.7483/OPENDATA.LHCb.HKJW.TWSZ |
| [18] | Schenke, B., & Venugopalan, R. (2014). Eccentric protons? Sensitivity of flow to system size and shape in p+ p, p+ Pb and Pb+ Pb collisions. Physical Review Letters 113, 102301. http://doi.org/10.1103/PhysRevLett.113.102301 |
| [19] | Buckley, A., & Whalley, M. (2010). HepData reloaded: reinventing the HEP data archive. arXiv preprint. |
| [20] | Khachatryan, V., et al. (CMS Collaboration) (2010). Transverse-momentum and pseudorapidity distributions of charged hadrons in pp collisions at √ s= 7 TeV. Physical Review Letters, 105(2), 022002. http://doi.org/10.1103/PhysRevLett.105.022002 |
| [21] | Zapp, K. C. (2014). Geometrical aspects of jet quenching in JEWEL. Physics Letters B, 735, 157-163. http://doi.org/10.1016/j.physletb.2014.06.020 |
| [22] | Mathiak, B., & Boland, K. (2015). Challenges in Matching Dataset Citation Strings to Datasets in Social Science. D-Lib Magazine, 21(1/2). http://doi.org/10.1045/january2015-mathiak |
| [23] | Meyer, C. A. (2008). Reference Accuracy: Best Practices for Making the Links. The Journal of Electronic Publishing, 11(2). http://doi.org/10.3998/3336451.0011.206 |
| [24] | INSPIRE blog (2012). HepData comes to INSPIRE. |
| [25] | CERN (2014). Press Release. "CERN makes public first data of LHC experiments". |
| [26] | ATLAS Collaboration (2013). Measurements of Higgs boson production and couplings in diboson final states with the ATLAS detector at the LHC. HEPData. http://doi.org/10.7484/INSPIREHEP.DATA.A78C.HK44 |
| [27] | Blomer J., Berzano D., Buncic P., Charalampidis I., Ganis G., Lestaris G, & Meusel, R. (2014). The Need for a Versioned Data Analysis Software Environment. arXiv preprint. |
| [28] | Fenner, M. (2015). Data Citation Support in Reference Managers. |
| [29] | Force, M. M., & Robinson, N. J. (2014). Encouraging data citation and discovery with the Data Citation Index. Journal of Computer-Aided Molecular Design, 28(10), 1043-1048. http://doi.org/10.1007/s10822-014-9768-5 |
| [30] | Lin, J., Cruse, P., Fenner, M., & Strasser, C. (2014). Making Data Count: A Data Metrics Pilot Project. UC Office of the President: California Digital Library. |
About the Authors
Patricia Herterich is a PhD candidate at the Berlin School of Library and Information Science and has worked as a data librarian at CERN's Scientific Information Service since 2012. Her research focuses on the information architecture and requirements of research data services for High Energy Physics. She also participated in the EC projects APARSEN, ODE and ODIN.
Sünje Dallmeier-Tiessen works at CERN. Dr. Dallmeier-Tiessen's research investigates opportunities to enable Open Science across disciplines. Within High-Energy Physics she designs and develops services to enable data sharing, data discovery and data citation. She co-chairs a Research Data Alliance Data Publishing group dedicated to "workflows" for sharing data and has authored many articles and reports on these subjects. From April to August 2015, she was based at Harvard University as a visiting scholar.
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |