| ||
D-Lib Magazine
|
|
|
Steve Hitchcock, Donna Bergmark*, Tim Brody, Christopher Gutteridge, Les Carr, Wendy Hall, Carl Lagoze*, Stevan Harnad |
![]()
AbstractThe speed of scientific communication — the rate of ideas affecting other researchers' ideas — is increasing dramatically. The factor driving this is free, unrestricted access to research papers. Measurements of user activity in mature eprint archives of research papers such as arXiv have shown, for the first time, the degree to which such services support an evolving network of texts commenting on, citing, classifying, abstracting, listing and revising other texts. The Open Citation project has built tools to measure this activity, to build new archives, and has been closely involved with the development of the infrastructure to support open access on which these new services depend. This is the story of the project, intertwined with the concurrent emergence of the Open Archives Initiative (OAI). The paper describes the broad scope of the project's work, showing how it has progressed from early demonstrators of reference linking to produce Citebase, a Web-based citation and impact-ranked search service, and how it has supported the development of the EPrints.org software for building OAI-compliant archives. The work has been underpinned by analysis and experiments on the semantics of documents (digital objects) to determine the features required for formally perfect linking — instantiated as an application programming interface (API) for reference linking — that will enable other applications to build on this work in broader digital library information environments. Introduction: Exploiting Open AccessImagine, as a researcher, the prospect of free, instant access, at any time, anywhere, to all peer reviewed papers and data that might affect your work. How much better would that be than the present situation? Such a prospect is achievable through the process of authors self-archiving their eprint papers in open-access archives that comply with the Open Archives Initiative (OAI). The power of this idea is permeating the scholarly publishing establishment. More libraries are beginning to host OAI-based open-access archives to present research papers produced by their institutions (Crow 2002). Progressive publishers are providing free online versions of journals, sometimes before, sometimes after, formal publication; new business models for open access journals are at last emerging. Even those that remain unconvinced by open access recognise the move to electronic publication must be accompanied by improved access. Publishers are collaborating as never before, among themselves and with digital libraries, to support new electronic services such as reference linking and mediated access based on powerful databases and new systems of identifiers and rights management. It's a serious business. In fact, only one group in the scholarly communication chain isn't yet embracing open access as much as it ought: authors (Pinfield 2002). This is curious, because authors stand to gain most in the switch to open access. Some fear damaging prestigious peer reviewed journals, but as is already apparent, journals are getting better because open access and self-archiving do not exclude other forms of publication and, focused by competition, journals will enhance their core values. Authors are well aware of the potential benefits of open access, but how can they be persuaded to act in pursuit of these benefits? The key requirements that scholarly authors demand of publication are visibility and impact. The key to determining impact is the ability to measure citations. The Open Citation Project grew out of an early demonstration of tools to add links, post-authoring, to references contained in scholarly papers in Web-deliverable formats. The basic idea was to extend the application to very large numbers of papers freely available on the Web. Linking on that scale would require automatic recognition and collection of references contained in these papers. If the references are stored in a database, it is possible to do more than link references: for a given paper, the number of times it has been referenced can be determined, and from this emerges the ability to measure impact. There is nothing new in this, except that impact has always been associated with journals and has typically been measured by expensive secondary services. Could it be possible that papers freely available on the Web might also have a measurable impact? And might this measurement be provided by a service that, like the papers it acts on, is free and could give authors (and research assessment agencies) an instant indication of the impact of their papers (Harnad 2001)? This is the story of the Open Citation Project, intertwined with the concurrent emergence of the OAI, which has become a focal point for open access to metadata describing all sorts of digital objects held by libraries hosting Open Archives. Open access, Open Archives, reference linking and citation analysis are all connected, we contend, in creating a managed digital library framework in which peer reviewed scholarly papers can be made freely accessible to all in the most efficient manner possible. The story begins with the transition from backwards-in-time reference linking to forward-in-time citation analysis on the Web, and the consequent potential to transform open access. While once there may have been wild projections for open access, the scenarios described above, involving publishers and libraries, are real and are an integral part of this story. From Reference Linking to Citation Analysis on the WebReference linking has become the de facto added value for electronic journals (Hunter 1998). In recent years there have been important reference linking initiatives. Journal publishers have converged on Digital Object Identifiers (DOIs) and CrossRef (Pentz 2001), described by Hellman (Hellman 2001) as a 'miracle'. The library community, which wants to solve the perennial 'appropriate copy' problem — getting the right resource to the right user at the right time — for the digital world (Caplan and Flecker 1999), appears to have selected the ingenious OpenURL (Van de Sompel and Beit-Arie 2001), a proposal for 'context-sensitive' linking (i.e., a service that knows which resources are available to a user) currently being fast-tracked towards standardisation by NISO. Web linking is not easy and raises social and cultural problems, for example, the misunderstanding of, and resistance to, deep linking by some commercial Web content providers. Reference linking similarly raises commercial as well as technical issues (Hitchcock et al. 1998b). Hellman referred to the 'unprecedented' cooperation between all the major science publishers through CrossRef, rather than to any implementation, but tensions remain (Quint 2002). Demonstration systems embracing these various linking components have raised hopes that heterogeneous and diverse information environments can be viewed by users as though they are a single delivery system (Beit-Arie et al. 2001), although some remain skeptical (Pace 2002). From the user perspective, reference links are remarkably useful, but in essence all the link does is save the user time. A formal reference given in a paper is an address to the cited work. Even without the link the referenced work ought to be retrievable. A link might save the user minutes or even weeks in retrieving the work — currently we can only speculate on the cognitive impact on scholarly research of instant and universal online retrievability, which Harnad calls 'scholarly skywriting' and which he predicts will 'increase individual scholars' productivity by an order of magnitude' (Harnad 1996). The real value in collected reference data is not in producing links that point to works in the past, the authored links, but in creating links that transport the user forward in time. For a given paper, what later works have cited it? Unlike the reference list, this cannot be an authored part of the original paper and cannot be determined by the reader independently. Citation analysis requires an additional service. It is possible to build a simple citation database by storing bibliographic records that contain the reference lists from papers. Hundreds of thousands of users of citation manager programs such as EndNote and ProCite recognise the utility of citation analysis for building personalised bibliographies (Simboli and Zhang 2002). Citation analysis is not new. The technique was first identified by Garfield and has since been exploited in information products from ISI, the company that Garfield formed. Garfield's brilliant insight was to recognise that references in journal papers can be used to form an intellectual index across the whole of a chosen literature. Such an index would be impossibly complex and costly to compile without author references: "by using authors' references in compiling the citation index, we are in reality utilizing an army of indexers" (Garfield 1955). More than that, the index can be used to measure the 'impact' of cited works. The more often a paper is cited, the more highly regarded the work is likely to be within the peer community. This factor has become a widely used, if contentious, measure of the importance of papers, authors and journals. This knowledge can in turn can be used by scholars new to a field to find starting points for exploring the literature. ISI has found a lucrative market for its products, indicating the high value that the research community places on tools that measure citation impact. Other abstract and indexing database services, such as the the American Chemical Society's Chemical Abstracts Service and American Mathematical Society's MathSciNet, have belatedly noticed the potential of including citing reference lists. Citation links have also crept into papers in the electronic versions of high-profile journals such as Science and Nature, drawing on secondary sources such as ISI. (Simboli and Zhang 2002). The advent of the Web has brought dramatic growth in the availability of journal papers online, many free of charge through services such as arXiv (ArXiv), and has opened new possibilities for citation analysis. With network access to works, it becomes possible to automate data collection from very large resources at relatively low cost, making it feasible for Web-based citation services to be offered free to users. NEC's ResearchIndex (Lawrence et al. 1999), CERN's Document Server (Claivaz et al. 2001) and Citebase, a citation and impact-ranked search service produced by the Open Citation Project, are examples. In contrast to ISI's established subscription services covering a self-selecting corpus of 6500 of the highest impact journals, ResearchIndex and Citebase are in their infancy, covering diverse collections, having to work with inconsistent data formats, and trying to identify user preferences to optimise their features. Progress is being made. ResearchIndex (ResearchIndex) currently indexes over a million computer science papers. Citebase is linked from over 200,000 arXiv records (currently on a trial basis), introducing the service to tens of thousands of prospective users. ArXiv links to Citebase appear below links to the Stanford Linear Accelerator Center (SLAC) SPIRES citation database in a typical abstract page (see foot of Figure 1). The SLAC-SPIRES service involves more manual labour in data collection and checking than the software approach of Citebase, and SLAC-SPIRES has been compiled over a longer period — since 1974 (O'Connell 2000). SLAC-SPIRES covers only high-energy physics, a large subset of arXiv, whereas Citebase indexes all papers in arXiv. The two are thus not directly comparable, but both emphasise the contentious nature of citation data with prominent warnings about coverage and interpretation.
Figure 1. Example arXiv abstract, showing links to SLAC-SPIRES and Citebase citation services (on 25th September 2002) The Open Journal (OJ) Project produced some of the first demonstrators of Web-based reference linking and citation analysis, but depended on data supplied from journal publishers and ISI (Hitchcock, et al. 1998a). Soon after this collaboration, ISI introduced Web of Science, making its citation indexes available on the Web for the first time (Atkins 1999). Starting in 1999, as the successor to the OJ project, the three-year Open Citation Project aimed to apply the tools and techniques from the earlier OJ work to open and freely accessible Web data, in particular to now mature eprint archives such as arXiv. The project combined the experience of reference linking specialists in Southampton University's IAM group with the expertise of digital library data management of the Digital Library Research Group at Cornell University. The third partner was arXiv, then based at Los Alamos and now hosted at Cornell. As the Open Citation (OpCit) Project completes its funding period, this article describes the broad scope of its work, showing how it has progressed from early demonstrators of reference linking to produce Citebase. This work was underpinned by analysis and experiments on the semantics of documents (digital objects) to determine the features required for formally perfect linking: an application programming interface (API) for reference linking. Along the route the project helped launch the OAI, with project principals leading the development of metadata and protocol schemes on which OAI is founded (Lagoze and Van de Sompel 2001). The project also supported the development of EPrints.org software to build OAI-compliant archives. Reference linking: OpCit in the digital library environmentOne original objective of the Open Citation Project, described by Hitchcock et al. (Hitchcock 2000), was to 'hyperlink', or produce reference links, for all the papers in the arXiv physics archives. The extension of that work to a build a citation database could be seen to be one of the primary contributors to the objective of promoting this new way of navigating the scientific journal literature based on free access and free services. At that time OAI was in its infancy. In terms of numbers of papers, access to eprints was, and still is, dominated by the centralised disciplinary-based arXiv. OAI instead decided to focus attention and responsibility on institutions for building and managing repositories, including eprint archives. Institutions — not disciplines or learned societies — share with their authors the benefits of enhanced usage and impact for their research output. To ensure the visibility of archive contents is not limited to institutions, the other key aspect of OAI is interoperability. If objects in an Open Archive are described by a defined protocol and metadata format, then the presence or availability of a work can be advertised to other, independent services. OAI based its model and technical infrastructure on NCSTRL (Networked Computer Science Technical Reference Library), which provided an index — now being revived within an OAI framework (Anan et al. 2002) — for browsing and searching papers from distributed collections made available by participating computer science departments. Thus, at the outset the project could foresee an information environment based on distributed, interoperable institutional archives in which digital libraries are distinguished by services that apply to various types of content. Mediating services would provide managed and enhanced access to free content (OpCit) or paid-for content (the established journal secondary services supplemented by CrossRef and DOIs) or, in some cases, both (resolver services such as SFX (Van de Sompel and Hochstenbach 1999). OpenURL was motivated by the need to standardise the way metadata describing cited resources is packaged within a URL so this information can be passed to resolvers such as SFX). There are two ways of presenting digital services to users. One is to modify the original content. An example is the project's early experiments with reference linking, illustrated by Hitchcock et al. (Hitchcock 2000). References were linked, indicated by boxes surrounding the linked text, from PDF versions of original papers. Overlaying services on content in this way is effective if it is offered at the place and moment the user needs it most. Otherwise this approach can appear intrusive and faces cultural resistance. Further, it can be difficult, not to say inappropriate, to add new information to the originally authored text. A more universally accepted way is to create information interfaces. Citebase: a new interface to the scholarly literatureAs the volume of networked metadata and content grows, interfaces become a powerful and flexible means of enabling users to explore this content. Interfaces in the digital environment are analogous to packaging in the physical world, embracing selection as well as access. What makes digital services, and digital libraries, so powerful is the degree of automation that can be implemented behind the user interface (Arms 2000). At its most effective, this processing must be transparent yet responsive to user demands, providing scope for user input and, for more advanced services, control. The resulting output must be organised optimally for user response. Search is the most familiar service on the Web, yet because most search engines compete to offer the most comprehensive coverage of the Web, the concept of selection is not immediately obvious. Instead, bare search services that have not evolved into portals are characterised by a simple user interface — a text box — and compete on the ability to provide fast processing and the most relevant results. In other words, the most successful search engines provide the desired result with minimal input and effort from the user by delegating almost all choices and almost the entire task to a highly sophisticated underlying algorithm and processor. In one case the underlying algorithm provides citation analysis with perhaps the ultimate accolade: a mass audience service, although it is unlikely many users are aware of the connection with citation analysis. The search service in question is Google, inevitably. Google has become enormously popular for the quality of its results — the ability to rank, at the top of the results, Web pages that satisfy the user's query (Brin and Page 1998). As well as indexing content, Google analyses links to Web pages. The technique works because links, like citations, are not offered lightly and represent intellectual connections between works. The number of links pointing to a page can be used to determine its relative importance among pages on similar topics and is the basis of Google's ranked results. The growth of OAI archives has motivated new search services, such as Arc (Arc) (Liu et al. 2001) and OAIster (OAIster), which cover all registered OAI-compliant data providers (DPs) rather than the Web (most OAI data providers are hidden to Web search engines, although software such as DP9 (DP9) can be used to build a gateway service for crawlers that require persistent URLs and HTML rather than XML for all OAI records). These services harvest and store OAI metadata records from OAI archives, so user search is based on these data rather than the data of the complete archived objects. Citebase — designed to be a "Google for the refereed research literature" because it ranks research results, in this case based on authored references to designated papers, not on Web links as Google does — exercises more selective coverage (Citebase). Data are harvested from the larger OAI disciplinary archives — currently arXiv, CogPrints (CogPrints) and BioMed Central (BioMed) — that (with permission) allow texts as well as metadata to be downloaded via an automated machine interface. Unlike the earlier OpCit reference linking demonstrator, Citebase does not store full documents but extracts the references, which are associated with the OAI metadata record for the document in which they are identified. This association between document records and references is the basis for a classic citation database, matching a cited document with the record for that document (reference linking) and matching a record with instances of its citation (forward citation analysis), i.e.:
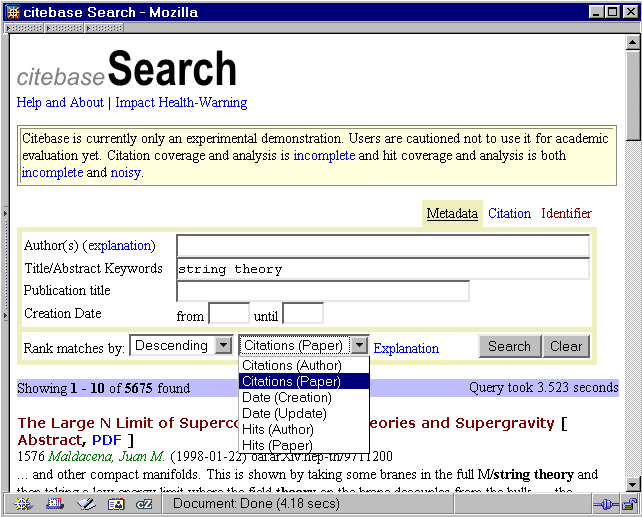
In this case, the citation database explicitly contains records for documents A and B. A record can be treated as a surrogate for the full text because it contains a direction (typically a URL) to the text. Although the existence of document C is known through its citation by A and B, it may not be possible to link to C if there is no harvested record for it. Whether C is known simply by citation or as a harvested record, it will always be possible to link from a citation of C to A and B, illustrating another benefit of linking forward in time to citing documents. The Citebase Web interface (Figure 2) shows how the user can classify the search query terms (typical of an advanced search interface) based on metadata in the harvested record (title, author, publication, date). In separate interfaces, users can search by archive identifier or by citation. What differentiates Citebase is that it also allows users to select the criterion for ranking results by Citebase processed data (citation impact, author impact) or based on terms in the records identified by the search, e.g., date (see drop-down list in Figure 2). It is also possible to rank results by the number of 'hits', a measure of the number of downloads and therefore a rough measure of the usage of a paper. This is an experimental feature to analyse both the quantitative and the temporal relationship between hit (i.e., usage) and citation data, as measures of impact. Hits are currently based on limited data from download frequencies at the UK arXiv mirror at Southampton only. The further use and interpretation of such data in the full Citebase service will be subject to further analysis and discussion.
Figure 2. Citebase search interface, showing results for the most-cited paper on string theory in arXiv (on 25th September 2002) The results shown in Figure 2 are ranked by citation impact: Maldacena's paper, the most-cited paper on string theory in arXiv at the time, has been cited by 1576 other papers in arXiv. By selecting the Abstract page for this paper (http://citebase.eprints.org/cgi-bin/citations?id=oai%3AarXiv%3Ahep%2Dth%2F9711200) the user is offered not just the abstract, but also citation data and a link to the full text. What distinguishes the Citebase record are the following data, placing the work in context of backward and forward citations, usage and impact:
Co-cited articles are articles that have been referred to in the same citing article. Where articles are co-cited many times (i.e., many articles cite both), the number of times can be summed to provide a co-cited score. Co-cited articles are likely to cover the same topic or argument, with the higher the number of co-citations, the more likely the articles are closely related. Citebase is based on classic citation principles adopted by other successful services and widely used in the community, but does this implementation work for users? There are a number of variables that need to be tested, and Citebase has been evaluated by arXiv users and by others who use or maintain bibliographic services to access the refereed journal literature. Results of that evaluation are being processed and will be reported first on the project Web site (OpCit Project). The aims of the evaluation were to:
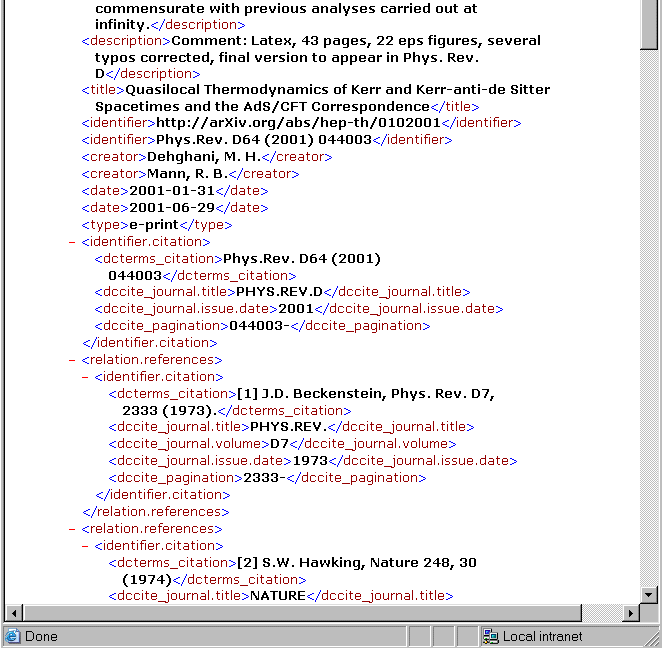
Development of Citebase will continue beyond the OpCit project. Of widest significance is the emergence of Citebase as a data provider as well as an OAI service provider. Citebase records will be available to automated harvesters just as though they were OAI records, although they are more complex and contain reference data (Figure 3). Researchers at Old Dominion University have harvested Citebase data as part of their Archon (Archon) federated digital library on physics (Liu et al. 2002), and arXiv is a possible (re)harvester of Citebase data too. Experiments are being performed with various metadata formats and XML schema for exporting reference data. One format designed for this purpose is the Academic Metadata Format (Krichel and Warner 2001). This is a 'local profile', i.e., nonstandard, format. Other possibilities are encoding citations in the OpenURL format, or using the structured-value set containing the sub-elements for citation proposed by the Dublin Core Citation Working Group (Dublin Core), which can be mapped to OpenURL attributes (Powell and Apps 2001). The difficulties of producing an agreed schema and format for citation metadata was highlighted on the OAI-implementers discussion list (OAI-implementers), thread XSD file for qualified DC).
Figure 3. Example Citebase record encoded in DC-Citation-like format for potential re-harvesting by other service and data providers Other planned enhancements include making Citebase reference links OpenURL-enabled, so pointing the links at library and journal services. This feature is being investigated by directing OpenURL links at a target resolver service. (Typically users should be able to select their preferred resolver, likely to be based in their institutional library.) In this case, the target resolver should ideally include Citebase data, so results presented to the user following a Citebase link might include a link back to Citebase as well as to other sources that might contain a referenced item. Citebase is a new, non-commercial service and so is unlikely to be included in resolvers supplied as part of library information systems (Hellman 2001). Citebase has a DP9 interface, principally to enable it to be indexed by Google and other Web search engines. It has been discovered that this needs to be optimised to enable Google to index the whole of Citebase: it is believed Google takes longer to index dynamically generated cgi-based services than static pages. This limited coverage of Citebase in Google has become less important now that arXiv is indexed by the search service (arXiv has had a long-standing policy blocking access to Web crawling software used by search engines), and now that Citebase is linked from records for arXiv papers. Ironically, the static arXiv links should ensure that Google indexes all of Citebase. Other OAI data and service providers may still need DP9 to assist indexing by Web search engines. API for Reference LinkingThere are many different applications for reference linking. The project at Cornell considered the question "what would be the ideal behavior of a digital object that supported reference linking (both incoming and outgoing)"? Answering this question led to an API with four principal methods:
Each component produced by these methods can be seen in a typical Citebase record, but this approach is more generalisable to other reference linking applications than that used to build Citebase. A few Java classes were defined to support reference linking in an object oriented way. These methods can be invoked on the surrogate, a special class in the API that encapsulates data regarding a particular online digital object. To use the API, a new surrogate is instantiated, passing it the URL of the online digital object for which information is to be gathered. Below is an example of a small Java program that uses the API to print out the references from an online journal article. // A program that prints out the References from an on-line article
import Linkable.API.Surrogate; // The API
public class PrintRef {
public static void main (String[] args) {
// create a Surrogate for ths given URL (parses the HTML)
Surrogate s =
new Surrogate ("http://www.dlib.org/dlib/may00/rudner/05rudner.html");
String rl = new String(s.getReferenceList());
System.out.println(rl);
}
}
The bulk of the analysis is done by the surrogate constructor, the single line, Surrogate s = new Surrogate(...); This call downloads the online work, turns it into XHTML, parses the XHTML, and extracts some information, such as citations and references. The next call on the API, String rl = new String(s.getReferenceList()) invokes the method that returns the references in the form of an XML document, which is then converted to a String and printed. The API is downloadable from the Cornell project site (Reference Linking API). It is anticipated that repositories will at some point contain reference linking data, so the API was later extended to support persistent storage of surrogates. Once a surrogate is instantiated, it can be saved to a repository, if desired. Thus one could build a repository of surrogates, which could later be re-instantiated and have the basic API methods invoked on them. (A second version of the surrogate constructor was written to resurrect saved surrogates.) API evaluationThe API was used to build several applications against online journals (D-Lib Magazine, Journal of Electronic Publishing, ACM Digital Library). With five methods (the original four, plus save) the API was found in our evaluations to be sufficiently usable. The main limitation of the software is that not all HTML pages are equally easy to analyse, e.g., some HTML is so badly written that it cannot be converted into XHTML and, therefore, cannot be parsed. This is likely to remain a problem on the Web for some time. A more complete description of the reference linking API and its evaluation, including the D-Lib application, can be found in Bergmark and Lagoze (Bergmark and Lagoze 2001). Also, a discussion of problems involved with the extraction of reference linking data is detailed by Bergmark (Bergmark 2000). RefLinking demonstratorA working application of the API turns HTML references in an online paper into live links that will fetch the referenced item. This demonstrator can be run from <http://cs-tr.cs.cornell.edu/RefLinkingDemo>. Using a Javascript-enabled browser, download the version of the paper with "<reflink> elements converted into JavaScript code by an XSLT stylesheet" (version 3 in the demonstrator), and try clicking on some references in the linked text (a dialogue box should appear, allowing the referenced paper to be downloaded). The reference linking API shows promise and should eventually be used as part of an OAI Service Provider. Filling the Archives: EPrints.org SoftwareReference linking and citation analysis only truly become effective when there is a critical mass of related, linkable content, whether that content is in open-access archives or journals. For open-access archives, even when aggregated, other than from those larger subject-focused archives covered by Citebase, there is as yet insufficient content for linking. It is possible the example of Citebase and arXiv will motivate authors in other areas to self-archive their papers, but the OpCit project hasn't just promoted the benefit of contributing to open-access archives by proxy example. It has also supported the development of software, known as EPrints.org software, to build and manage OAI-compliant archives. EPrints software is undoubtedly the better known product of the OpCit project. It could be argued that Citebase or similar services will ultimately have more impact with users, but EPrints is necessary now and plays a critical role in enabling open-access archives to be filled. EPrints has evolved from software first developed to manage the CogPrints cognitive science eprint archive. CogPrints was functionally modelled on arXiv, but was based on entirely original software. With the emergence of OAI and the consequent emphasis on institutional archives, it was evident there would be a need for large numbers of archives smaller than arXiv, but which would need to operate on similar principles — low cost, largely automated deposit, indexing and dissemination of author-archived content. CogPrints software was rewritten by Rob Tansley to make it OAI-compliant, and then to make it generic, so it could be used as EPrints, which was further developed within the remit of the Open Citation project to generalise the author and management interfaces for open-access archives. Of most significance, EPrints builds archives that comply with the OAI Protocol for Metadata Harvesting (PMH). This means that any content deposited within an EPrints-based archive will become visible to users of OAI services, such as the search services mentioned above, immediately enhancing the chances of discovery. Authors depositing papers in an EPrints archive are not required to have any knowledge of OAI metadata: it is generated automatically. EPrints is aimed at institutions and special-interest communities. In its current incarnation, the name GNU EPrints (GNU) reflects that it is open source and freely available under the GNU General Public License and conforms to the strict GNU guidelines for free software. The last major release of EPrints, version 2.0, appeared in February 2002, although it has been updated (now on version 2.1.1) to conform with the latest OAI-PMH (also version 2) announced in June. Features of EPrints version 2 include:
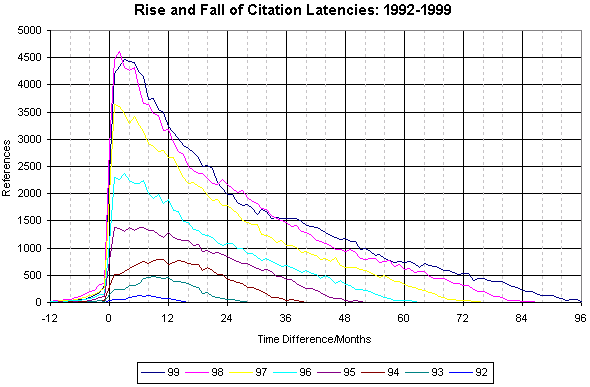
The practicalities of building an EPrints-based archive are described by Nixon (Nixon 2002). Meanwhile, EPrints has new features that extend its focus on institutional research papers. It is now configurable for adoption as a journal-archive for new open access journals or established journals converting to open access, e.g., Psycoloquy (Psycoloquy). There are plans to extend EPrints for structured data handling in, for example, e-science applications, enabling subparts of very large data archives to be used in analysis without the need to copy contents in their entirety to the processing site. OpCit and OAI: Improving the InfrastructureThere has been a surge of activity based on OAI, reflected in research programs and projects, tools, data and service providers (Van de Sompel and Lagoze 2002). The faith of early adopters has proved well founded, but some repository administrators had their fingers crossed: "As we have introduced our repository to our faculty and staff, we have emphasized the point that because they would be depositing their material in an OAI-compliant archive, it would automatically and painlessly be discoverable from various other points around the globe. Luckily, we were right." Roy Tennant (Tennant) A primary motivator for adoption of OAI has been its promotion by funding agencies such as JISC in the UK (see Beyond the Project below), the NSF, Digital Library Federation (DLF) and the Mellon Foundation (Waters 2001) in the USA, as well funding from new programmes such as the Budapest Open Access Initiative (Budapest) sponsored by George Soros' Open Society Institute. In Europe activity is focused on the Open Archives Forum (OAF) and other projects funded by the EU's Information Society Technologies 5th Framework (IST-FP5) Programme. The results of these recent initiatives, and the dramatic increase in momentum they have lately provided for eprints and for institutional self-archiving, have been chronicled by Suber (Suber 2002). The Open Citation project has contributed to OAI not just as a data and service provider, but in other, lower profile ways concerned with enhancing the efficiency of OAI through registration and validation services, aggregation and building infrastructure. At its simplest, basing the OAI-PMH on unqualified Dublin Core metadata say, interoperability ought to be straightforward in principle. In practice, unqualified DC is not mandated, and there are various reasons why the quality of OAI data for harvesting can be compromised. Liu et al. (Liu 2001) discovered that not all archives strictly follow the OAI protocol, many have XML syntax and encoding problems, and some data providers are periodically unavailable. One solution is for data providers to be validated for protocol compliance, but not all data providers register. The registration and validation service provided by OAI, and managed by Donna Bergmark at Cornell, has other benefits. Registered archives become accessible by service providers, and validation helps improve repository maintenance. To simplify registration, EPrints feeds repository URLs straight into the OAI registration process (if so desired by the EPrints administrator). A scan of the list of registered sites (OAI sites) shows many have used EPrints to build repositories. To improve interoperability, scalability and reliability of OAI services, OpCit has worked with the Old Dominion University team on infrastructure components such as proxies and caches (Liu et al. 2002). Proxies, transparent layers acting between data providers and harvesters, can be used to fix simpler encoding errors as part of the delivery process. More serious errors in the data require an intermediate storage approach: caching and aggregation. In this case a few large service providers might harvest and cache metadata from registered OAI repositories, reducing the load on those archives and serving many smaller harvesters. An OAI aggregator (OAIA) must in principle be an active cache as it requests new records from known repositories in advance so it is always up-to-date. An example OAIA known as 'Celestial' (Celestial), which mirrors OAI repositories, has been built by Tim Brody from the OpCit team. Usage and Impact: OpCit Data MiningOAI is winning support from repository administrators because it has a simple and, mostly, effective infrastructure. This feature alone will be insufficient to attract authors to deposit works in open-access archives. Many authors perceive, incorrectly, that open-access archives are competing with other sources, such as journals, for submissions. The role of open-access archives is to complement journals while establishing distinctive benefits for authors. The most compelling benefit any source can offer to authors is scholarly/scientific impact — the visibility, uptake, usage, and eventually the citation of their research by other researchers — along with the recognition, resources, and prestige these bring. Open-access archives, because they are free to authors and users, maximise access to works and will therefore maximise impact. The latter prediction may still sound hypothetical, but it is already beginning to be substantiated by quantitative (Lawrence 2001) and qualitative (Odlyzko 2002) evidence. According to Lawrence: "the greatest impact of online availability is yet to come, because comprehensive search services and more powerful search methods have become available only recently." The OpCit project project has access to over 10 years of ArXiv papers and can identify how citation patterns have changed over that time. Correlations have been made with (admittedly limited) data on usage of arXiv taken from the arXiv mirror at Southampton since August 1999. The raw results of this work can be found in Mining the Social Life of an Eprint Archive (Mining). Interpretation is complex, but we can present at least two results that confirm the prediction that open access enhances impact (Figure 4a and Figure 4b).
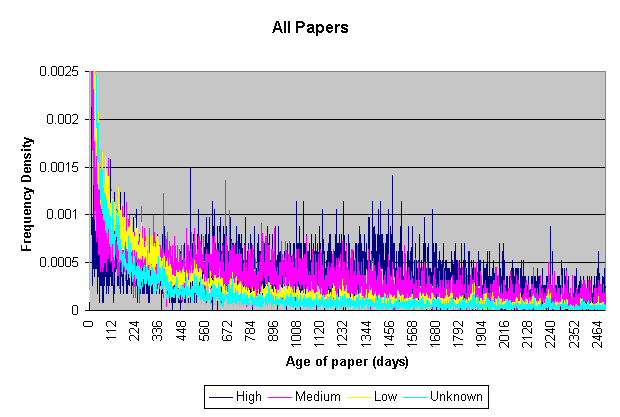
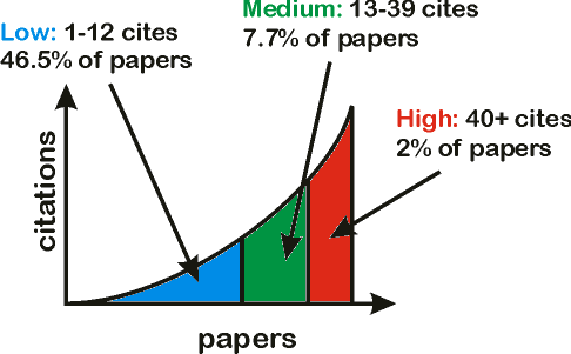
Figure 4a shows how, over a period of eight years to 1999, the peak of citations occurs higher and sooner for papers deposited in each succeeding year. The citation peaks for 1999 and 1998 can be seen after approximately 3-4 months. This is remarkable because it implies that the speed of scientific communication — the rate of ideas affecting other researchers' ideas — is increasing dramatically. As with any large collection of papers, there is a wide variation in the likelihood of any individual paper being cited. Analysis of citations identified papers in arXiv that might be categorised as high, medium and low impact papers. From 132,218 papers in arXiv at the time of the analysis, 595,698 internal citations were extracted, an average of 4.51 citations per paper. The papers were split so that approximately 1/3 of the citations were to each category of impact. Papers with no citations to them are referred to as 'unknown'. The number of papers in each category is shown in Table 1 and graphically in Figure 5. Returning to Figure 4b, which shows accesses to papers in each category, it becomes clear that high impact papers are accessed more often and over a more sustained period than other types of paper. What is not clear from this analysis alone is whether higher accesses are due to higher citations, or higher citations are due to higher accesses, but either way the result is dependent on unrestricted, free access. The relationship between access and impact is worthy of further study, but what can already be said is that a clear hierarchy of papers emerges, based entirely on previously unrecognised usage patterns within arXiv. Brody et al. (Brody 2002) explore further results from this work, showing how arXiv supports an evolving network of texts commenting on, citing, classifying, abstracting, listing and revising other texts. Archives are becoming a network of texts rather than simply a classified collection of texts.
It has to be recognised that impact depends on more than access; another factor is association, with an established journal title, say. Journal reputations are founded on peer review. Figure 4 shows that informed authors can have all three benefits — peer review, access and impact — simply by depositing a paper in an open-access archive at the same time as submitting to a peer reviewed journal. Revised versions can similarly be submitted to both sources simultaneously. For a given paper, publication in a peer reviewed journal is recognised in the updated OAI record. Intuitively, authors — and journal publishers too — know that unrestricted access enhances impact. The biomedical field, which has the largest number of high-impact journals (Garfield 1996), has least reason to alter its publishing practices, yet initiatives such as NIH's PubMed Central (PubMed) and the Public Library of Science (Public) are evidence that authors now demand more. Publishers may not have warmly embraced NIH's demand for deposit of published papers in its freely accessible archive, yet those journals that contribute to PubMed Central do so without compulsion and are clearly sensitive to their authors' demands as reflected by the Public Library of Science. It is no coincidence that a biomedical journal publisher, BioMed Central, has produced the most convincing publishing model so far for open access journals (Velterop 2002). It is gradually becoming clearer that in the online age archives and journals will play complementary roles in scholarly communication and publication. Journals will continue their established tradition of providing the essential service of peer review (Harnad 1998). Meanwhile, OAI open-access archives will facilitate access, and OAI services such as Citebase will measure usage and impact. Beyond the OpCit ProjectThe ideas and efforts that have characterised OpCit will be taken forward not just in the obvious products of the project, such as Citebase and GNU EPrints, but in new environments as well. Specifically, the JISC FAIR programme (JISC), which is just beginning, includes major projects that will seek to extend the culture of EPrints-based archives in UK universities through the provision and targetting of new archives and supplementary services:
Conclusion: What we have learnedThe Open Citation project has produced tools to help OAI data providers and service providers. The project has been fortunate in being able to contribute to the broadly-based activities, focused on OAI, that have emerged since 1999 to support improved scholarly communication through open access to research papers. We are clear this is the beginning of a transformation towards more open access, not its end. New tools will emerge to help users and promote authors, for example, Paracite (Paracite), a new software agent and search interface for parsing and locating raw references on the Web. Open citation data will be visualised using simple citation and co-citation mapping tools. Two preliminary demonstrators have been produced by the project: Beyond this there is also the need to expose and link the research data on which papers are based in open and freely accessible forms, building on the work of the nascent 'e-science' and 'grid' development programmes designed to enable distributed global collaborations on very large data collections across the Internet. In this context, it can be seen just how embryonic current investigations are. The longer-term future is thus exciting, yet uncertain. The legacy of a project, however, should be borne of experience rather than speculation, so we offer some concluding thoughts which, although stated before, collectively give a clear picture of the way forward:
AcknowledgementThe Open Citation Project is funded by the Joint NSF - JISC International Digital Libraries Research Programme. References
[Anan] Anan, H. et al. (2002) "Preservation and Transition of NCSTRL Using an OAI-Based Architecture". Proceedings of the Second ACM/IEEE Joint Conference on Digital Libraries, Portland, Oregon, July.
[Arc] Arc search service, <http://arc.cs.odu.edu>. [Archon] Archon, <http://archon.cs.odu.edu>.
[Arms] Arms, W. Y. (2000) "Automated Digital Libraries: How Effectively Can Computers Be Used for the Skilled Tasks of Professional Librarianship?" D-Lib Magazine, Vol. 6, No. 7/8, July/August.
[ArXiv] arXiv, <http://arxiv.org/>.
[Atkins] Atkins, H. (1999) "The ISI Web of Science - Links and Electronic Journals". D-Lib Magazine, Vol. 5 No. 9, September 1999.
[Beit-Arie] Beit-Arie, O. et al. (2001) "Linking to the Appropriate Copy: Report of a DOI-Based Prototype". D-Lib Magazine, Vol. 7, No. 9, September
[Bergmark 2000] Bergmark, D. (2000) "Automatic Extraction of Reference Linking Information from Online Documents". Technical Report TR 2000-1821, Cornell Computer Science Department, November
[Bergmark 2001] Bergmark, D. and Lagoze, C. (2001) "An Architecture for Automatic Reference Linking". 5th European Conference on Research and Advanced Technology for Digital Libraries (ECDL),Darmstadt, September. [BioMed] BioMed Central, <http://www.biomedcentral.com/>.
[Brin] Brin, S. and Page, L. (1998) "The Anatomy of a Large-Scale Hypertextual Web Search Engine". Seventh International World Wide Web Conference, Brisbane, April.
[Brody] Brody, T., Carr, L. and Harnad, S. (2002) "Evidence of Hypertext in the Scholarly Archive". Proceedings of HT'02, the 13th ACM Conference on Hypertext, University of Maryland, June.
[Budapest] Budapest Open Access Initiative, <http://www.soros.org/openaccess/read.shtml>.
[Caplan] Caplan, P. and Flecker, D. (1999) "Choosing the Appropriate Copy". NISO News, September.
[Celestial] Celestial, <http://celestial.eprints.org>.
[Claivaz] Claivaz, J.-B. et al. (2001) "From Fulltext Documents to
Structured Citations: CERN's Automated Solution". HEP Libraries Webzine,
Issue 5, November. [Citebase] Citebase, <http://citebase.eprints.org/cgi-bin/search>. [CogPrints] CogPrints, <http://cogprints.soton.ac.uk/>.
[Crow] Crow, R. (2002) "The Case for Institutional Repositories: A SPARC Position Paper". Scholarly Publishing & Academic Resources Coalition, Washington, D.C., July.
[DLF] Digital Library Federation, <http://www.diglib.org/architectures/testbed.htm>. [DP9] DP9, <http://www.cs.odu.edu/~dlibuser/dp9>. [Dublin Core] Dublin Core Citation Working Group, <http://www.dublincore.org/groups/citation>. [E-Prints] E-Prints UK, <http://www.rdn.ac.uk/projects/eprints-uk>.
[Garfield 1955] Garfield, E. (1955) "Citation Indexes for Science: A New Dimension in Documentation through Association of Ideas". Science, Vol. 122, No. 3159, July 15, 108-111.
[Garfield 1996] Garfield, E. (1996) "The Significant Scientific Literature Appears in a Small Core of Journals". The Scientist, Vol. 10, No. 17, September 2nd, 13, 16.
[GNU] GNU EPrints, <http://software.eprints.org>.
[Harnad 1996] Harnad, S. (1996) "Implementing Peer Review on the Net: Scientific Quality Control in Scholarly Electronic Journals". In Scholarly Publication: The Electronic Frontier, edited by Peek, R. and Newby, G (Cambridge, MA: MIT Press), pp. 103-108.
[Harnad 1998] Harnad, S. (1998) "The invisible hand of peer review". Nature [online] (c. 5 November).
[Harnad 2001] Harnad, S. (2001) "Research Access, Impact and Assessment". Times Higher Education Supplement, Vol. 1487, 18 May, p. 16.
[Hellman] Hellman, E. (2001) "Building a database for e-journals". Web4Lib Electronic Discussion, 17th October.
[Hitchcock 1998a] Hitchcock, S. et al. (1998) "Webs of Research: Putting the User in Control". Internet Research and Information for Social Scientists (IRISS) 1998 Conference, Bristol, March.
[Hitchcock 1998b] Hitchcock, S. et al. (1998) "Linking electronic journals: Lessons from the Open Journal project". D-Lib Magazine, December.
[Hitchcock 2000] Hitchcock, S. et al. (2000) "Developing services for open eprint archives: globalisation, integration and the impact of links". Proceedings of the Fifth ACM Conference on Digital Libraries, June (ACM: New York), pp. 143-151.
[Hunter] Hunter, K. (1998) "Adding Value by Adding Links". Journal of Electronic Publishing, Vol. 3, No. 3, March.
[JISC] JISC FAIR programme<http://www.jisc.ac.uk/dner/development/programmes/fair.html>.
[Krichel] Krichel, T. and Warner, S. (2001) "A metadata framework to support scholarly communication". International Conference on Dublin Core and Metadata Applications 2001, Tokyo, October
[Lagoze] Lagoze, C. and Van de Sompel, H. (2001) "The Open Archives Initiative: Building a Low-Barrier Interoperability Framework". Joint Conference on Digital Libraries, Roanoke, VA, June.
[Lawrence] Lawrence, S. (2001) "Free Online Availability Substantially Increases a Paper's Impact". Nature Web Debate on e-access, May.
[Lawrence & Giles] Lawrence, S., Giles, C. L. and Bollacker, K. (1999) "Digital Libraries and Autonomous Citation Indexing". IEEE Computer, Vol. 32, No. 6, 67-71.
[Liu 2001] Liu, X. et al. (2001) "Arc - An OAI Service Provider for Digital Library Federation". D-Lib Magazine, Vol. 7, No. 4, April.
[Liu 2002] Liu, X. et al. (2002) "A Scalable Architecture for Harvest-Based Digital Libraries - The ODU/Southampton Experiments". arXiv.org, Computer Science cs.DL/0205071, May.
[Mining] Mining the social life of an eprint archive, <http://opcit.eprints.org/tdb198/opcit/> and <http://opcit.eprints.org/ijh198/>. [OAF] Open Archives Forum, <http://www.oaforum.org/index.php>.
[Nixon] Nixon, W. (2002) "The evolution of an institutional e-prints archive at the University of Glasgow". Ariadne, issue 32, July.
[OAI-aggegator] OAI Aggregator 'Celestial', <http://celestial.eprints.org>. [OAI-implementers] OAI-implementers discussion list, thread: XSD file for qualified DC, <http://www.openarchives.org/pipermail/oai-implementers/2002-June/000518.html>. [OAI sites] OAI registered sites, <http://www.openarchives.org/Register/BrowseSites.pl>. [OAIster] OAIster search service, <http://oaister.umdl.umich.edu/cgi/b/bib/bib-idx?c=oaister;page=simple>.
[O'Connell] O'Connell, H. B. (2000) "Physicists Thriving with Paperless Publishing". arXiv.org, Physics/0007040, February.
[Odlyzko] Odlyzko, A. (2000) "The rapid evolution of scholarly communication". Economics and Usage of Digital Library Collections (PEAK) conference, Ann Arbor, MI, March.
[OpCit e-Services] OpCit e-Services citation visualisation, <http://www.ecs.soton.ac.uk/~srk/opcit/>. [OpCit Project] OpCit project Web site, <http://opcit.eprints.org>. [Paracite] search for raw references on the Web, <http://paracite.eprints.org>.
[Pace] Pace, A. K. (2002) "'Standard' Issue: Defining Standards and Protocols". Computers in Libraries, Vol. 22, No.8, September.
[Pentz] Pentz, E. (2001) "CrossRef: A Collaborative Linking Network". Issues in Science and Technology Librarianship, Winter.
[Pinfield] Pinfield, S., Gardner, M. and MacColl, J. (2002) "Setting up an institutional e-print archive". Ariadne, issue 31, April.
[Powell] Powell, A. and Apps, A. (2001) "Encoding OpenURLs in Dublin Core metadata".
Ariadne, issue 27, March.
[Psycoloquy] Psycoloquy open access journal, <http://psycprints.ecs.soton.ac.uk/>. [Public] Public Library of Science, <http://www.publiclibraryofscience.org/>. [Pubmed] PubMed Central, <http://www.pubmedcentral.nih.gov/>.
[Quint] Quint, B. (2002) "The Digital Library of the Future: CrossRef Search and QuestionPoint offer challenges to traditional services". Information Today, Vol. 19, No. 7, July/August.
[Reference linking API] Reference linking API, <http://www.cs.cornell.edu/cdlrg/Reference%20Linking>. [RefLinking] RefLinking demonstrator, <http://cs-tr.cs.cornell.edu/RefLinkingDemo>. [ResearchIndex] NEC ResearchIndex, <http://citeseer.nj.nec.coma>. [RoMEO] RoMEO project, <http://www.lboro.ac.uk/departments/ls/disresearch/romeo/index.html>. [SHERPA] SHERPA project, <http://www.sherpa.ac.uk/index.html>.
[Simboli] Simboli, B. and Zhang, M. (2002) "Citation Managers and Citing-Cited Data". Issues in Science and Technology Librarianship, Summer.
[Suber] Suber, P. (2002) "Momentum for eprint archiving". Free Online Scholarship
Newsletter, 8th August
[TARDIS] TARDIS project, <http://tardis.eprints.org>. [Tennant] Tennant, R., on American Scientist September-98 Forum, June 2002, <http://www.ecs.soton.ac.uk/~harnad/Hypermail/Amsci/2085.html>.
[Van de Sompel 1999] Van de Sompel, H. and Hochstenbach, P. (1999) "Reference Linking in a Hybrid Library Environment, Part 2: SFX, a Generic Linking Solution". D-Lib Magazine, Vol. 5, No. 4, April.
[VandeSompel 2001] Van de Sompel, H. and Beit-Arie, O. (2001) "Open Linking in the Scholarly
Information Environment Using the OpenURL Framework". D-Lib Magazine, Vol. 7, No. 3, March.
[Van de Sompel 2002] Van de Sompel, H. and Lagoze, C. (2002) "Notes from the Interoperability Front: A Progress Report from the Open Archives Initiative". 6th European Conference on Research and Advanced Technology for Digital Libraries (ECDL),
Rome, September.
[Velterop] Velterop, J. (2002) "BioMed Central. What we do and what we don't do".
American-Scientist-E-PRINT-Forum, August 14th.
[Waters] Waters, D. J. (2001) "The Metadata Harvesting Initiative of the Mellon
Foundation". ARL Bimonthly Report, No. 217, August.
[XGQuery] XGQuery citation visualisation <http://www.cs.cornell.edu/cdlrg/Reference%20Linking/XGQuery.html>. (6 November 2002 - Author's name corrected in references above from Simbol to Simboli.) Copyright © Steve Hitchcock, Donna Bergmark, Tim Brody, Christopher Gutteridge, Les Carr, Wendy Hall, Carl Lagoze, and Stevan Harnad |
||||||||||||||||
| |
||||||||||||||||
|
Top | Contents | ||||||||||||||||
| | ||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/october2002-hitchcock
|