|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
March/April 2015
Volume 21, Number 3/4
Development of Linked Data for Archives in Korea
Ok Nam Park
Sangmyung University, Republic of Korea
ponda@smu.ac.kr
DOI: 10.1045/march2015-park
Abstract
The study reported on here converts records of National Archives of Korea to linked data, and connects archives data to library and museum data in order to show how linked data are actually used in MLA (Museum-Library-Archives). This research analyzed the data structure of the National Archives of Korea and ontologized data into linked data. To produce RDF/OWL data from the data sources, this research used Dublin Core and SKOS (Simple Knowledge Organization System). TopBraid Composer™ was utilized as the ontology design tool. The linked data for the National Library of Archives enabled search by collocation, and free search between archival records through visualization and SPARQL. A flexible linking from archival data to authority data was shown. The interlinking with library and museum data enabled users to find information from various datasets. Limitations in the existing records search system were addressed and improved through linking. Linked data established in this way actualized empirical studies that prove the benefit of libraries, museums and archives data integration. It will contribute to increasing the possibility of reusing data in the National Archives of Korea. In addition, the modeling provided by this research can be used for modeling linked data.
1 Introduction
The flood of information now in libraries, archives and museums has changed the information paradigm. People no longer just consume information from one type of information center, but instead long to utilize diverse types of information across libraries, archives and museums (Choi and Rieh, 2012). There is a new trend called MLA (Museum-Library-Archives) or Larchivium (Library-Archives-Museum) for adapting to the new paradigm. Libraries, archives and museums share similar functions in that they provide information and services for users. MLA purports to promote services by integration of functions in an effort to overcome redundancy and inefficiency. Significant effort has been made for MLA. Library and Archives Canada integrates the National Library of Canada and the National Library and Archives of Canada to distribute information on the cultural heritage of Canada as well as archive information. MLA Council has delved into development of a cooperation business model and services (Choi and Rieh, 2012). Methods for spatial composition, functional planning, and policy development for cooperation were studied (Choi, 2008; Choi and Rieh, 2012; Choi, 2014; Kim, 2012). However, most efforts were limited to external merging of libraries, archives and museums. To support true MLA services, information integration is required. More distinctive methods of information acquisition and sharing are emphasized in order to gather scattered information on MLA in meaningful ways.
For information integration of MLA, this research employs linked data. Linked data, proposed by Berners-Lee (2006), is a method for production and sharing of data on the web. Its aim is to allow both humans and machines to explore and understand the data on the web based on URIs and RDF (Resource Description Framework). After Berners-Lee emphasized the significance of linked data, the Linking Open Data Project was initially started around DBPedia, a RDF version of Wikipedia. Global attention to data sharing using linked data has increased. The areas have been expanded to various fields, including private companies, libraries, and public government.
Library of Congress, LISBRIS (Swedish National Union of Catalog), National Library of Germany, Library of CERN (European Organization for Nuclear Research), National Library of Hungary, National libraries of UK, Czech Republic, and Finland, and OCLC published, or are currently implementing, library data as linked data. The National Library of Korea has also established a foothold for configuration of linked data for bibliographic data and authority data since 2011. Governments including the U.S. government and U.K. government are also moving rapidly in opening data sets to the public and implementing linked data in order to achieve creative utilization of data. The Korean government opens public data in Excel format and anticipates the development of applications using data sets by private sectors.
Despite the emerging discussion of linked data, researchers do not specifically spell out how open data are mashed up with other data. Most projects continue opening data under the name of linked data. The purpose of this research is to convert records in National Archives of Korea into linked data and to connect archives data to data from libraries and museums to display how linked data are actually used in MLA. While libraries and museums tend to open data, archives data is still isolated from the outside world. Even though the Europeana project has published its data sets for museums, libraries and archives around Europe, research for MLA data integration customized for the Korean environment has not yet been conducted. The previous study (Park, 2012) concentrated on converting authority data of archives into linked data. This study expands to ontologize archival records, associate authority data with archival records, and interlink data sets in archives with other data sets. The case "Korean War" was selected to present concept demonstration of linked data of archives.
The results of this research will foster the conversion of archival data in Korea into linked data on a large scale. The results of this research will make the system of the National Archives of Korea more pragmatic and open using linked data, leading the national and global information fusion of data in the MLA context in the future. It contributes to true sharing of recorded data and the inter-operational capability of MLA.
2 Related Work
Miller (2011) commented on the utilization of linked data in libraries and its potential for application to libraries. He presented the value of linked data in portability, data disclosure, and creativity to solve problems. He notes that the development of linked data is already underway and libraries should investigate methods for assigning URIs, principles of linked data publication, and ways to leverage library data to the Web of data.
Agenjo, Hernandex and Viedma (2012) noted a need for linked data for authority data for the Polymath Virtual Library. The status of library collections was reviewed. The library contains works by Spanish, Portuguese, Brazilians, and Hispanic Americans along with diverse subjects. Authority records include the name, biographical information, occupation, family relationships, affiliation and membership, philosophical schools and movements, influence and professional relationships to other authors. For this contextualization of authority records, they emphasized that linked data should establish semantic relationships.
Baker (2012) emphasized that Dublin Core is practical for libraries in order to shift from Web of Documents to Web of Data. He noted that Dublin Core with RDF supports "harmonization with related standards"; ISBD, FRBR, and RDA are rendered into RDF; and Dublin Core has been associated with other sets of vocabularies over the years.
Ding, Peristeras and Hausenblas (2012) presented a roadmap of linked open government data for three phases. In the open phase, raw data should be in open format so that people can easily retrieve it. In the second phase, users link data to create value-added services by machine and human aids. The final stage is for reuse such as presenting visual mash-up services. To facilitate linked open data, data should be barrier free, links beyond DBpedia should be made, and collaborative networks are to be considered by mapping vocabularies and/or sharing library open data application.
Shadbolt, et al. (2012) pointed out efforts in opening government data sets to the public and implementing linked data in order to promote open access and reuse of the government's public information. They mentioned lessons from the Data.gov.uk linked data project of the U.K., which integrates data using semantic web technology and extended the search functions. However, hard-to-link format, widely adoptable metadata standards, and coreference resolution problems remain to be studied further in the future.
Gracy, Zeng and Skirvin (2013), who conducted a preliminary study for music linked data, researched metadata structure of music from 11 linked data sets and developed a model to map the metadata structure of music to library collections. As a result, only limited properties, including title, name, and physical characteristics were matched since MARC and DC are more general in semantics than properties in music collections. Given this difficulty of crosswalking, they concluded that linked data would improve federated search and browsing, enhance access to library data, and reduce redundancy of data creation.
Vila-Suero and Gomez-Perez (2013) presented applications of linked data to libraries. The datos.bne.es project, using MARC records in the National Library of Spain, is constructed with a linked data structure. The project employed MARiMbA as a tool and FRBR as a model for linked data. The project follows phases — specification, modeling, generation, linking, publication, and exploitation. The bibliographic records and authority data are transformed into classes with properties.
Moulaison and Million (2014) pointed out that linked data is spreading rapidly in the field of libraries, however, it is not clear how it can be implemented for library domains and how it supports finding and browsing. For libraries, linked data as disruptive technologies, dereferenceable HTTP URIs for identification of objects on the Web, conflicting discussion about linked data standards, and operational tools for information discovery should be researched further as well as comprehensible use cases.
The review shows that linked data can be applied to various areas, with good effect. The use of URIs, RDF/OWL for semantic web languages and common vocabularies such as Dublin Core, FOAF, and SKOS, and languages such as RDF, has been considered. Implementation and openness of ontology-based linked data should be taken care of first in order to reuse and share the data. Empirical studies for data mash-up, and computing approaches for effective and efficient data curation, should be continued.
3 Research Methods
3.1 Analysis
National Archives of Korea cataloged records based on standards — ISAD (G) (General International Standard Archival Description) for archival records, ISAAR (International Standard Archival Authority) for authority records of creators, and their own subject vocabularies. The search system in National Archives of Korea also offers some tips for data structure. These standards and the search system were analyzed to investigate data structure of National Archives of Korea.
3.2 Modeling
Data modeling for National Archives of Korea was performed before converting data into linked data using RDF/OWL. RDF (Resource Description Framework) is a framework to describe information with subject, predicate, and object. OWL (Web Ontology Language) is an ontology language for describing resources of the web based on class, properties, and relationship. RDF/OWL is a semantic web standard data model for machine readable web, which is pursued by linked data.
In adopting a data model for RDF/OWL, the following principles were applied. First stage classifies Class and Property. Class means "kinds of things" in ontology. To define a thing as a class, a few criteria were considered — whether a thing has instances, a thing has characteristics as properties, users expect to collocate information based on a thing, and a thing has relationships with other things such as a hierarchical relationship. For example, "Actor" and "Work" can be classified as classes in a movie domain. The actor information is described by diverse properties, such as name, date of birth, place of birth, and winning careers. By doing so, users locate movies based on actor and work. "Angelina Jolie" is an instance of an actor. "Spider-Man" is an instance of work. Second, the name of a class is of the form noun, and starts with upper case. The name of a property is of the form verb, and starts with lower case. Third, properties were classified according to Datatype Property, Object Property, and Annotation Property. Object property is for connecting resources to one another, Datatype Property is for resources and values, and Annotation Property is for expressing cases in which values of resources are in a form of annotation.
3.3 Implementation
To produce RDF/OWL data from the data sources, this research used Dublin Core and SKOS (Simple Knowledge Organization System). TopBraid Composer™, the ontology modeling tool with a GUI environment that complies with the W3C semantic web standard, was used as the ontology design tool. A URI was assigned for each term in vocabularies.
3.4 Interlinking
Linked data suggests links for resources or vocabularies for data integration. It proposes owl:sameAs for links among resources, and skos:exactMatch, skos:broadMatch, skos:narrowMatch, skos:relatedMatch, and skos:closeMatch for links among vocabularies. owl:sameAs denotes that resources linked by owl:sameAs are identical and apply to records in this study. Links among vocabularies are employed for subjects. skos:exactMatch links terms with identical meaning, skos:broadMatch relates to broader terms, skos:narrowMatch to narrower terms, skos:relatedMatch to related terms, and skos:clos. To enable data-interoperability between other knowledge assets, National Library of Korea, DBPedia, and War Memorial of Korea were utilized.
4 Results of Research
4.1 Analysis
Archival data in Korea was cataloged based on ISAD (G) (General International Standard Archival Description), which identifies elements that should be contained in an archival finding aid. Archival data is classified into seven areas - identity statement area, context area, content and structure area, condition and access and use area, allied materials area, notes area, and description control area. Each area is classified according to multiple elements. Archival data includes the hierarchy — collection, series, file, and item. The record is classified at a detailed level based on its hierarchical structure. Besides ISAD (G) elements, there are additional elements, which are applied to a specific level of record. For example, Management ID, Document Number, and Pages are only valid to item level of records. In addition, we need to pay attention to archival finding aids. The search system provides diverse options for browsing — Record type (document, government publications, picture/film, register, etc.), Online (offline, online), Category (diplomacy, economy/finance, national defense/union, social welfare, etc.), and Openness (open to public, closed).
4.2 Modeling
Record was modeled as a main class. Collection, Series, File, and Item were defined as Super/Subclass relationships, and hasPart / isPartOf were defined as object properties to express the hierarchies between records. hasPart and isPartOf were also defined as inverse properties so that inverse relationships among records can be referenced. To indicate related records, the class Record has a recursive relationship with itself by a relation property. Therefore, a relation property is labeled as a symmetric property. RecordType, Category, Online, and Openness were named as classes to support browsing. Seven areas to describe a record were classified according to Property and elements of each area into Sub-Property so that the sources of elements of each area can be described and identified through the relationship between Property and Sub-Property. Modeling is specified in Figure 1.
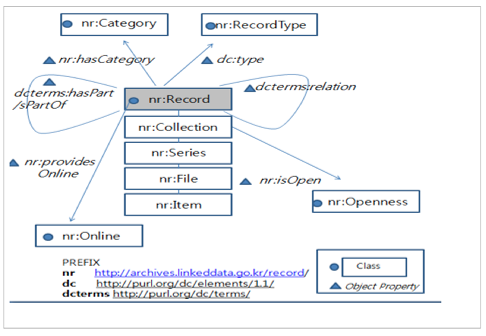
Figure 1: Modeling for Archival Data
Each property was classified using Object Property, DataType Property, and Annotation Property of OWL, and Dublin Core were used to their maximum extent. However, the property vocabularies that cannot be reused were extended (refer to Table 1).
| Structure | Property Type | Vocabulary | Level | Notes |
| Identification Statement Area | Object Property | nr:Identity | Property | |
| Reference Code(s) | DataType Property | nr:reference_code | SubProperty | |
| Title | DataType Property | dc:title | SubProperty | |
| Date(s) | DataType Property | dc:date | SubProperty | |
| Broader Record/Narrower Record | Object Property | dcterms:hasPart/dcterms:isPartOf | SubProperty | Inverse Property |
| Record Type | Object Property | dc:type | SubProperty | Link to nr:RecordType |
| Extent and Medium of the Unit of Description | DataType Property | nr:extent_medium | SubProperty | |
| Context Area | Object Property | nr:context | Property | |
| Name of Creator(s) | Object Property | dc:creator | SubProperty | Link to na:entity |
| Administrative/Biographical History | Annotation Property | nr:administrative_history | SubProperty | |
| Archival History | Annotation Property | nr:archival_history | SubProperty | |
| Acquisition Transfer History | Annotation Property | nr:acquisition_transfer_history | SubProperty | |
| Acquisition Transfer Source | Object Property | nr:acquisition_transfer_source | SubProperty | Link to na:entity |
| Acquisition Transfer Methods | Annotation Property | nr:acquisition_transfer_methods | SubProperty | |
| Content and Structure Area | Object Property | nr:content_structure | Property | |
| Scope and Content | Annotation Property | dc:description | SubProperty | |
| Index Term | Datatype Property | nr:index | SubProperty | |
| Appraisal, Destruction and Scheduling Information | Annotation Property | nr:appraisal_destruction_scheduling | SubProperty | |
| Accurals | Annotation Property | nr:accurals | SubProperty | |
| System of Arrangement | Annotation Property | nr:system_arrangement | SubProperty | |
| Conditions of Access and Use Area | Object Property | nr:condition_of_access_use | Property | |
| Conditions Governing Access | Annotation Property | nr:conditions_governing_access | SubProperty | |
| Use Environment | Annotation Property | nr:use_environment | SubProperty | |
| Conditions Governing Reproduction | Annotation Property | nr:conditions_governing_reproduction | SubProperty | |
| Language/Scripts of Materials | DataType Property | dc:language | SubProperty | |
| Physical Characteristics and Technical Requirements | Annotation Property | nr:physical_technical_requirements | SubProperty | |
| Online Service | Object Property | nr:providesOnline | SubProperty | Link to nr:Online |
| Allied Materials Area | Object Property | nr:allied_materials | Property | |
| Existence and Location of Originals | Annotation Property | nr:existence_location_originals | SubProperty | |
| Related Units of Description | Object Property | dcterms:relation | SubProperty | Recursive Relationship |
| Publication Note | Annotation Property | nr:publication_note | SubProperty | |
| Other | Object Property | nr:other | Property | |
| Record Category | Object Property | nr:hasCategory | SubProperty | Link to nr:Category |
| Record Openness | Object Property | nr:isOpen | SubProperty | Link to nr:Openness |
| managementID | Datatype Property | nr:managementID | SubProperty | Limit to File |
| Document Number | Datatype Property | nr:document_number | SubProperty | Limit to Item |
| Page Information | Datatype Property | nr:pages | SubProperty | Limit to Item |
| Management Organization | Datatype Property | nr:management_organization | SubProperty | Limit to Item |
| Service Provider | Datatype Property | nr:service_provider | SubProperty | Limit to Item |
Table 1: Vocabulary for Archival Record
4.3 Implementation
Record data modeled in such a way was implemented based on RDF/OWL. The following graph of RDF/OWL from TBC shows the connection of record to related classes through object type, and it becomes obvious that the relationship between records is expressed based on the modeled vocabularies. (refer to Figure 2).
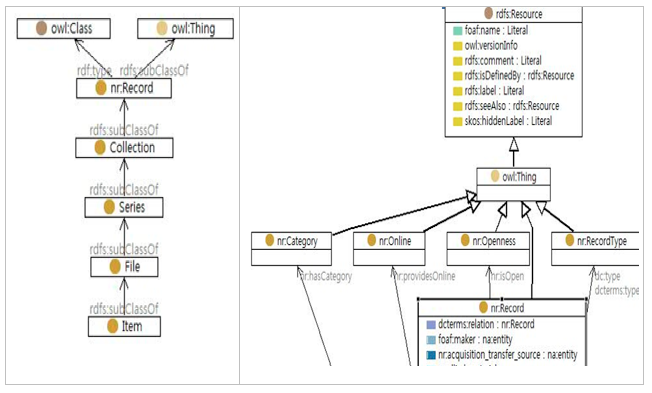
Figure 2: Graph with archival data
OWL Data was stored in Database by GUI interface (Figure3). Data can be browsed through visualization. Figure 4 shows hierarchy of the record such that series (AG27_S28, 한국전쟁 (Korean War)) has the collection (AG27, 외교통상부 (The Minister of Foreign Affairs and Trade)) as a higher record, and the file (CA0002072, 한국전쟁휴전일지 (Korean War Armistice Agreement)) and item (CA0002072-1, 한국전쟁휴전일지 (Korean War Armistice Agreement)) as lower records. Users can easily see that the resource (AG27_S28, 한국전쟁 (Korean War)) belongs to the level of series. In addition, the overall information of the record — AG27_S28 can be viewed from the expansion of the record, as shown in Figure 4. This enables searching for relationships between data and provides easier access to the data.
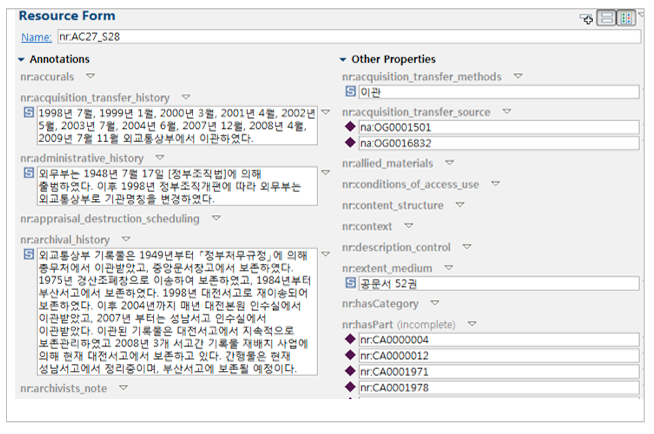
Figure 3: Data Entry Interface
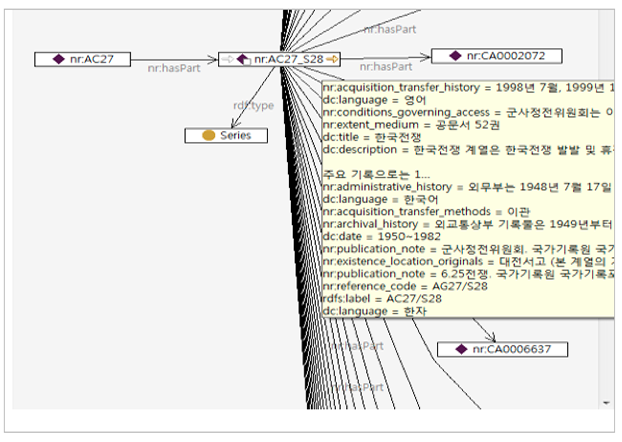
Figure 4: Visual Graph for archival records
4.4 Linking Record Data and Authority
Before linking record and authority data, authority records were converted to linked data. A detailed explanation of conversion of authority records into linked data was presented in a previous study (Park, 2012). Subject, subject heading, type, and subject field are modeled by the way in which class and other elements of the subject authority are modeled as properties. Subject type classifies subjects according to type, such as business, conference, convention, event, etc. Subject field categorizes subjects according to broad subject areas, such as national defense, unity, public order, public affairs, etc. Each subject concept is related to other concepts by broader, narrower, and related relationships. For creator, creator and creator type are modeled as classes. The creator type classifies creators according to affiliations such as National Administrative, Local Administrative, Education Administrative, and Legislation Organization. Each creator is classified into a detailed group based on its hierarchical structure, and also denotes predecessor/successor of the creator to represent organization history. The production authority data modeled in such a way was implemented based on RDF/OWL.
Each record is related to organizations as creators of the record and acquisition/transfer sources, and specifies concepts as subjects. These relationships are indicated by connecting archival records to authority data. The established ontology and record data were connected using the creator (dc:creator), acquisition/transfer source (na:acquisition_transfer_source) and subject (dc:subject) object properties (Figure 5).
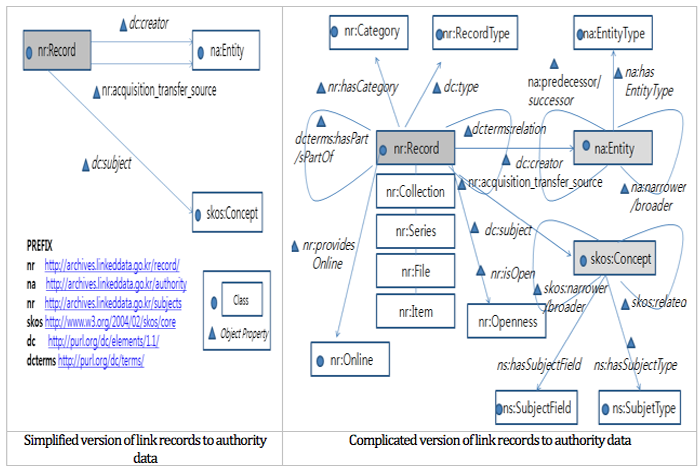
Figure 5: Links Archival Data to Authority Data
By connecting records to authority data, each record identifies the creator and subject. Detailed information on creator and subject are also provided by browsing. In the following example, the record with an identifier — CA0004786 — has 한국전쟁 (Korean War) as a subject. Also, by clicking 한국전쟁 (Korean War), all records with 한국전쟁 (Korean War) as a subject, as well as detailed information on the subject, such as scope Note, are recognized (Figure 6).

Figure 6. Archival Data to Authority Data Browsing
4.5 Interlinking
Linked data suggests links for resources or vocabularies for data integration. For data interlinking, datasets from the National Library of Korea, DBPedia, and The War Memorial of Korea were employed. DBPedia provides abstract, casualties, territory, thumbnail, photo collection, current status, date, and place of "Korean War", and allows downloading its datasets in RDF. National Library of Korea has converted authority data and bibliographic data into linked data since 2011, and partially opens its dataset in RDF. National Library of Korea presents altLabel, scopeNote, changeNote, and broader/narrower/related terms for "Korean War", and bibliographies related to "Korean War". The War Memorial of Korea includes people related, battlefield, relics information about "Korean War" and this dataset can be accessible from Data.go.kr in excel format.
The research employed owl:sameAs for connection of Archival data to DBPedia, and skos:exactMatch to connect a subject concept from Archives to subject concepts in National Library of Korea and The War Memorial of Korea in Figure 7.
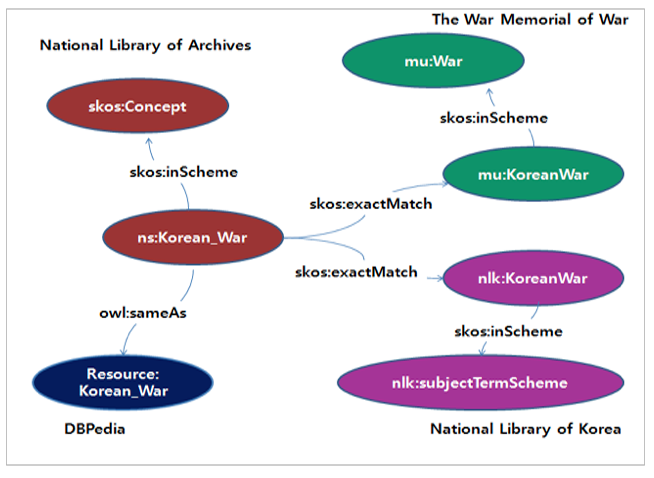
Figure 7. MLA linked data model
By interlinking data in National Archives of Korea with other data, information beyond National Archives of Korea can be accessed. By integration with DBPedia, users can easily see information about the Korean War from DBPedia by clicking Korean_War in owl:sameAs. It provides different labels, pictures related to the Korean War, URL, and address of Flickr. Interlinking with data from the War Memorial of Korea is accessed by skos:exactMatch. Clicking 6.25 presents information about the Korean War from the War Memorial of Korea. It introduces people, battlefields, and relics of the Korean War. In addition, when users click on a person (e.g., 고길훈 소장, Major General Ki-lHoon Ko), information about these people can be viewed, including picture, identifier, location, date, etc. For linked data with the National Library of Korea, when users click 한국전쟁 (Korean War) from the National Library of Korea, information about a subject concept such as preflabel, altlabel, related terms, scopeNote, and related bibliography is accessible. Clicking a specific title (e.g., 16세 소년의 절규, The scream of a 16-year-old boy), information about that title is introduced from visualization as well (Figure 8).
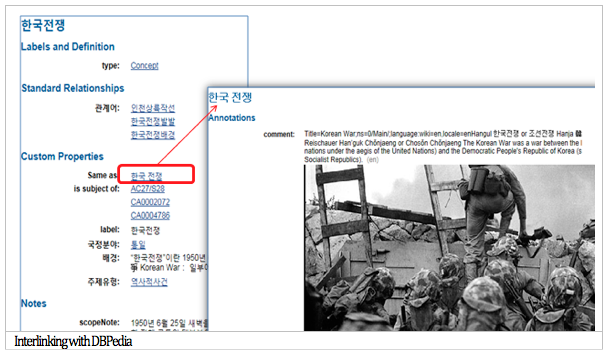
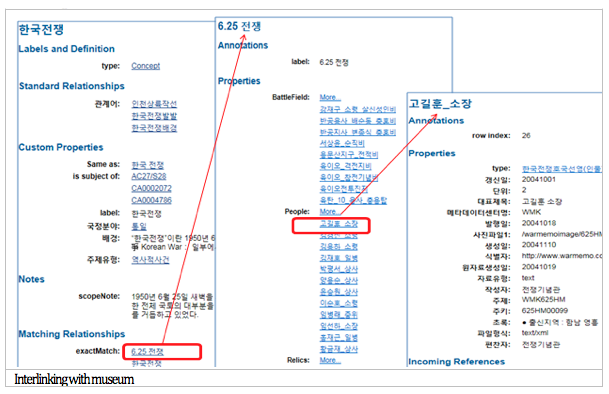
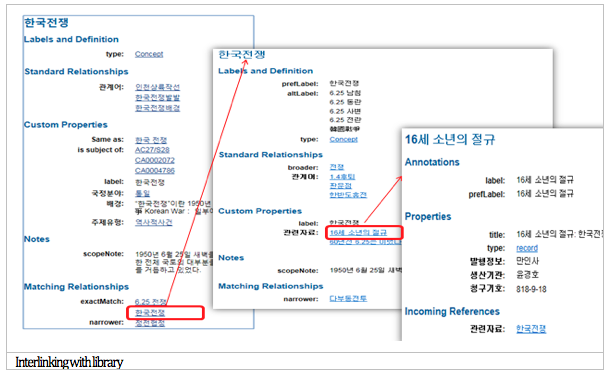
Figure 8. MLA linked data Example
5 Implications
5.1 Collocation
The linked data system supports collocation, which is the function of metadata. In the following (Figure 9), collocation extends browsing based on similar types of information. The record with an identifier, AG27_S28, provides diverse records belonging to the narrower level of AG27_S28 by a hasPart relationship. The records, which have the same creator (OG00035882) and record type (general document), can be viewed from visualization. From this, records with the same subject (Korean War) are expanded by collocation.
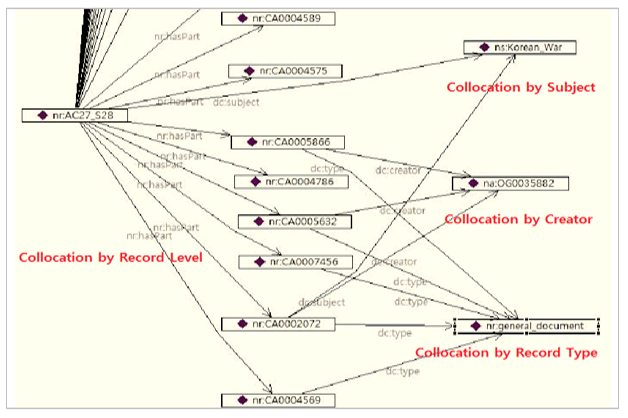
Figure 9. Collocation by Visualization
5.2 Reference
The linked data also offers powerful incoming reference. In the following example, once the record (한국전쟁 휴전일지 1953, Korean War Armistice Agreement 1953) indicates a creator (외교통상부 문화협력국 외교사료과, The Minister of Foreign Affairs and Trade-Cultural Cooperation — The Department of Diplomatic and Historic Materials), the creator automatically references records created by the specific creator. The symmetric properties or inverse properties defined in the records are also referenced. Therefore, predecessors and successors of the organization (외교통상부, The Minister of Foreign Affairs and Trade) are automatically positioned. That is, incoming relationship makes bidirectional access possible.

Figure 10. Incoming Reference
5.3 Query
Searching OWL data was implemented through SPARQL query. SPARQL, which stands for Simple Protocol and RDF Query Language, consists of prefix, select, and where. Prefix specifies data cells to select, Select for variables with ? and *, and Where for conditions. SPARQL employs triples — subject, predicate, and object since it is based on RDF. The following example is the output of the searches for a record with the identifier CA0002072. The search for a record provides all of the properties and values for those properties related to the record. The search for a property such as isOpen retrieves all records associated with this property, meaning that SPARQL enables users to search the data-base, not the document itself.
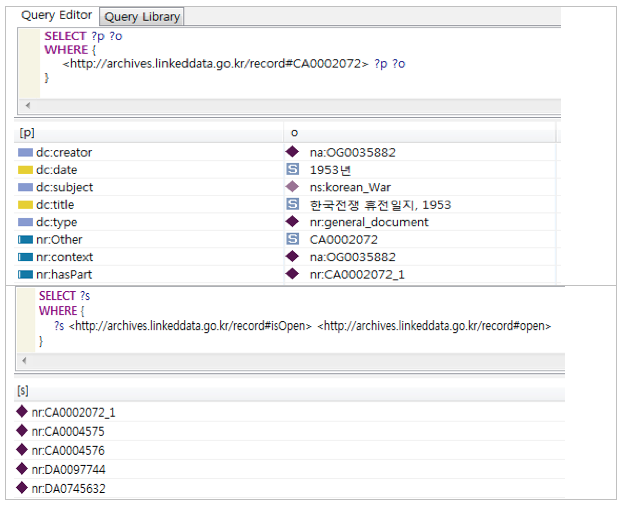
Figure 11. SPARQL Search
5.4 Data Integration
Data Integration based on linked data is the future of information management. URI based interlinking by owl:sameAs and skos:match integrates information from various sources and allows users to discover the needle in the haystack in one place. This MLA interlinking generates associative information about an object. MLA linking for "Korean War" displays information on bibliography, exhibitions, and relics in regard to "Korean War" as well as information from archives. It supports users' learning about an object, and users' serendipitous findings.
6 Conclusion
This effort to change the information environment around libraries, archives, and museums showed that the existing data processing methods are inadequate. The study suggests utilization of linked data for true integrated service for libraries, archives, and museums. The aim of this research was to convert the records of the National Archives of Korea into linked data as a foothold for Museum-Library-Archives (MLA) data integration, and connect datasets of the National Library of Korea and War Memorial of Korea to display MLA data integration. "Korean War" was selected as a case for linked data. Opening up and linking data in the National Archives of Korea are essential to utilizing those records, since open archival records as datasets are not yet published in Korea. This study analyzed the structure and search system for the National Archives of Korea, ontologized a data set, and converted the ontologized data into linked data. RDF/OWL was employed as a technical standard for records; Dublin Core and SKOS (Simple Knowledge Organization System) as vocabularies.
Free extension of archival records, search between archival records, a search by collocation of diverse class types of records, and access to detailed data of records were enabled through visualization and SPARQL. Creating a flexible linking of archival data and authority data extended the search from archival data to authority data and vice versa. Research for linking with other data sets, such as library and museum data sets, was pursued in order to implement the link required in the linked data. This link enabled users to find information from various datasets. The limitation in the existing records search system through link was improved.
Linked data established in this way actualized empirical studies meant to prove integration of libraries, museums and archives data. It can achieve not only free utilization through a link between record data and other data sets, but it can facilitate publishing data on the web as well, and it will contribute to increasing the possibility of reusing data in the National Archives of Korea. This will be an opportunity to expose the existence of the record data to wider audiences beyond the current users, and it will increase the value of information and improve the level of utilization (Park, 2012). In addition, the modeling provided in this research can be used for modeling datasets for other archives as a foothold for those efforts. This study was constrained to converting limited archival data in Korea into linked data to prove concept demonstration of linked data of archives. Data conversion of archival data in Korea should be continued going forward. Data shall be open and made electronically accessible to the public. Research for linking with other data sets, such as library, museum, and archive data sets, in other countries shall be continuously pursued in the future in order to implement the use of linked data. Further study should be conducted for URI publication, URI registry and vocabulary registry for MLA. User-friendly search interfaces beyond SPARQL shall be implemented. For linked data, efforts to select core data sets, convert them into a form of linked data, and interlink with other data optimized for needs, should be made continuously in order to prove the potential of linked data.
Acknowledgements
This work was supported by the National Research Foundation of Korea Grant funded by the Korean Government (NRF-2012S1A5A8023472).
References
[1] Agenjo, X., Hernandex, F. and Viedma, A. (2012), "Data aggregation and dissemination of authority records through linked open data in European context", Cataloging and Classification Quarterly, Vol. 50 No. 8, pp. 803-829. http://dx.doi.org/10.1080/01639374.2012.711441
[2] Baker, T. (2012), "Libraries, languages of description, and linked data: a Dublin Core perspective", Library Hi Tech, Vol. 30 No. 1, pp. 116-133. http://dx.doi.org/10.1108/07378831211213256
[3] Berners-Lee, T. (2006), "Linked data — Design Issues".
[4] Choi, J.H. (2008), "A case study on the MLA as an example of the national level cooperation between cultural institutions", The Korean Journal of Archival Studies, Vol. 8 No. 2, pp. 61-74.
[5] Choi, Y.S. and Rieh, H.Y. (2012), "Functional planning of Larchivium that integrate the functions of archives, libraries and museum", Journal of Korean Biblia Society for Library and Information Science, Vol. 23 No. 4, pp. 457-477.
[6] Choi, Y.S. (2014), "A study on analysis of remodeling target institution for Larchivium spatial planning", Journal of the Korean Society for Information Management, Vol. 30 No. 2, pp. 143-167.
[7] Ding, L., Peristeras, V. and Hausenblas, M. (2012), "Linked Open Government Data", IEEE Intelligent Systems, Vol. 27 No. 3, pp. 11-15. http://dx.doi.org/10.1109/MIS.2012.23
[8] Gracy, K.F., Zeng, M.L. and Skirvin, L. (2013), "Exploring methods to improve access to music resources by aligning library data with linked data: a report to methodologies and preliminary findings", Journal of the American Society for Information Science and Technology, Vol. 64 No. 1, pp. 2078-2099. http://dx.doi.org/10.1002/asi.22914
[9] Kim, Y.S. (2012), "A study on perspectives of the National Assembly Larchivium: Focused on discussion about collaborative strategies of memory institutions", The Korean Journal of Archival Studies, Vol. 12 No. 3, pp. 93-115.
[10] Miller, E. (2011), "Linked data and libraries", The Serials Librarian: From the Printed Page to the Digital Age, Vol. 60 No. 1-4, pp. 17-22. http://dx.doi.org/10.1080/0361526X.2011.556427
[11] Moulaison, H.L. and Stanley, S.N. (2013), "Beyond failure: potentially mitigating failed author searches in the online library catalog through the use of linked data", Journal of Web Librarianship, Vol. 7 No. 1, pp. 37-57. http://dx.doi.org/10.1080/19322909.2013.738562
[12] Park, O.N. (2012), "The Design and Development of Linked data in National Archives of Korea", Journal of Korean Biblia Society for Library and Information Science, Vol. 23 No. 2, pp. 5-25.
[13] Shadblot, O., Berners-Lee, G., Glaser, H. and shraefel, M.C. (2012), "Linked Open Government Data: Lessons from Data.gov.uk", IEEE Intelligent Systems, Vol. 27 No. 3, pp. 16-24.
[14] Vila-Suero, D. and Gomez-Perez, A. (2013), "datos.bne.es and MARiMbA: an insight into library linked data", Library Hi Tech, Vol. 31 No. 4, pp. 575-601. http://dx.doi.org/10.1108/LHT-03-2013-0031
[15] Villaz-Terrazas, B., Vilches-Blázquez, L.M., Corcho, O. and Gómez-Pérez, A. (2011), "Methodological guidelines for publishing government linked data", in Wood, D. (Ed.), Linking Government Data, Springer, Berlin, pp. 27-49.
About the Author
 |
Ok Nam Park is an assistant professor in library and information science at Sangmyung University. Her research interests include metadata, semantic web, and linked data. Her research has appeared in Knowledge Organization and Proceedings of the American Society for Information Science and Technology, as well as diverse journals of the Republic of Korea. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |