
By most accounts, knowledge management will be the "killer app" of the coming decade. In this article, we claim that it is in this application domain that we should expect to see digital library technology making its commercial and industrial presence felt. We describe the various factors that are driving digital libraries from research to serious commercial use, and we illustrate how these factors come together in a commercial digital library product suite, developed by Zuno Ltd.
As activities such as electronic commerce take off, we can expect to see an increased demand for solutions that can cope with the collection, management, analysis, and interpretation of various information sources to make more intelligent, timely, and effective transaction-related decisions. Performance of these and a number of other information-intensive tasks (e.g. publishing product brochures and data sheets, online selling of merchandise, monitoring and filtering of online sources of information for competitive intelligence and demographic profiling, customer order tracking, inventory management) will require the use of advanced information and knowledge management techniques such as those provided by digital libraries. Of course, these tasks will become more difficult as both the sources and uses of the information grow in number. For example, in a commercial environment, one of the most important activities to support will be the sharing of information, not just among different divisions within the company (e.g. marketing, sales, engineering), but also between the company and other related external parties (e.g. customers, partners, suppliers, distributors).
In this article, we argue that we are currently witnessing a crossover from the development of prototypical or research-quality systems to the widespread commercial use of advanced digital libraries for the Internet, World Wide Web (WWW), and corporate intranets. This is evidenced by the current level of commercial investment into providing and deploying sophisticated information and knowledge management solutions for networked users; besides Zuno Ltd.'s own products, witness the solutions offered by such companies as Fulcrum, Inference, Inso, Intraspect, Lotus, Open Text, Oracle, PLS, Quarterdeck, Tierra Communications, and Verity, among others. We argue further that the levels of commercial interest and investment will increase substantially over the next several years and that these will both leverage and quicken the pace of the crossover. Most critically, perhaps, we argue that the key enabling technologies are sufficiently developed at present for the commercial deployment of digital libraries.
The remainder of this article is structured as follows. In the following section, we describe the human and organizational imperatives that are driving digital libraries into the mainstream. We then describe how several disparate strands of research and development in computer and information sciences have provided the technological imperatives for this breakthrough. We then show how these human, organizational, and technological factors come together in a commercial digital library product suite, developed by Zuno Ltd. Finally, we speculate on the outlook for the commercialization of digital library technology.
TopThe Internet, and in particular its most famous offspring, the WWW, has revolutionized the way most of us do business and how we go about our daily working lives. In the past several years, the proliferation of personal computers and other key technologies such as client-server computing, standardized communications protocols (e.g. TCP/IP and HTTP), Web browsers, and corporate intranets have dramatically changed the manner in which we discover, view, obtain, and exploit information. Once little more than an infrastructure for electronic mail and a playground for academic users, the Internet has increasingly become a vital information resource for commercial enterprises which want to keep in touch with existing customers or reach new customers with new online product offerings, and which need to keep abreast of their competitors strengths and weaknesses.
With the increases in volume and diversity of use to which the WWW is being subjected comes an increasing demand from its users for sophisticated information and knowledge management services, above and beyond searching and retrieving. Examples of such services include cataloguing and classification, resource discovery and filtering, personalization of access and monitoring of new and changing resources, among others. While the number of professional and commercially valuable information resources available on the WWW has grown considerably over the last 2 to 3 years, relying on general-purpose Internet search engines to satisfy the vast and varied requirements of corporate users is quickly becoming an untenable proposition.
One of the most obvious difficulties from the point of view of users searching content on the WWW is the well known "information overload" problem [1]. People are frequently overwhelmed by the sheer amount of information available, making it hard for them to filter out junk and irrelevancies and focus on what is important, and also to actively search for the right information. At the same time, users easily become bored or confused while browsing the WWW. The hypertext nature of the WWW, while making it easy to link related documents together, can also become disorientating - the "back" and "forward" buttons provided by most browsers are better suited to linear structures than the highly connected graph-like structures that underpin the WWW. This can make it hard to understand the topology of a collection of linked WWW pages. Finally, the WWW was not really designed to be used in a methodical way. It is telling that the process of using the WWW is known as "browsing" rather than "reading" or "researching". Browsing is a useful activity in many circumstances, but it is not generally appropriate when attempting to answer complex, important queries.
In addition to such user-level problems with using the WWW, there are also a number of organizational factors that make the WWW difficult or inefficient to use, particularly in a commercial context. Perhaps most importantly, apart from the (very broad) HTML standard, there are no standards for how a WWW page should look. In particular, there are no widely used standards for metadata [2], or semantic markup, which would allow content providers to annotate their pages with information defining the content of each page. There are some good reasons for this, chief among them being that beyond obvious metadata elements such as author, title, format, and date, there is no real consensus on what is useful or practicable to associate with a given document; there are also significant technical problems with formalisms for defining document content.
Another problem is the cost of providing online content. Unless significant information owners can see that they are making money from the provision of their content, they will simply cease to provide it. How this money is to be made is probably the dominant issue in the development of the WWW today. As it currently stands, the WWW has a number of features that limit it as an "information market". Many of these stem from the fact that the WWW has academic origins, and as such, it was designed for free, open access. The WWW was thus not designed for commercial purposes, and in particular, no consideration at design-time was given to issues such as:
In order to realize the potential of the Internet, and overcome the limitations discussed above, we require a framework that:
The Internet is often referred to as a digital library. In fact, it is not. To see why, consider that a library is not simply a roomful of books; it is a roomful of books together with services. The minimal service we would expect of a library is indexing, so that we could find desirable information easily. Better libraries provide richer services. For example, a good librarian would know about the library's users, and use this knowledge in their interests. Such a librarian would, for example, not simply search for books or articles when specifically asked, but would pro-actively offer relevant content to a user, as it became available. With the exception of some (fairly crude) search facilities, the Internet offers none of these services.
If one adopts Clifford Lynch's definition of a digital library to be that of an "electronic information access system that offers the user a coherent view of an organized, selected, and managed body of information" [3], then one can argue that meeting the above functional requirements in the real world will necessitate the deployment of industrial-strength digital library systems.
Real world applications of digital libraries are many and varied. As well as leveraging online access to numerous large document collections (such as those owned by the worlds academic and public libraries), digital library technology will play a central role in promoting a number of other applications such as distance learning (by personalizing students access to stored materials), electronic commerce (through the provision of value-added directories and catalogues of goods and other rich customer-oriented services), and intranet knowledge management (by empowering corporate users to cope with the flood of information that must be managed on a day-to-day basis).
TopWe have argued that there are compelling reasons to believe that digital library technology is about to cross over from research-oriented demonstrator technology to industrial strength systems. The human and organizational issues discussed above are two causes of this crossover. But the crossover is also being driven by a number of technological factors. In this section, we argue that recent developments in Artificial Intelligence (AI), Human-Computer Interaction (HCI), multi-agent systems, the Internet/WWW, and library/information sciences have created both the infrastructure upon which viable large scale distributed digital libraries may be built, and the techniques and tools with which to implement such libraries. Figure 1 summarizes the main technological developments that feed into and promote this crossover.
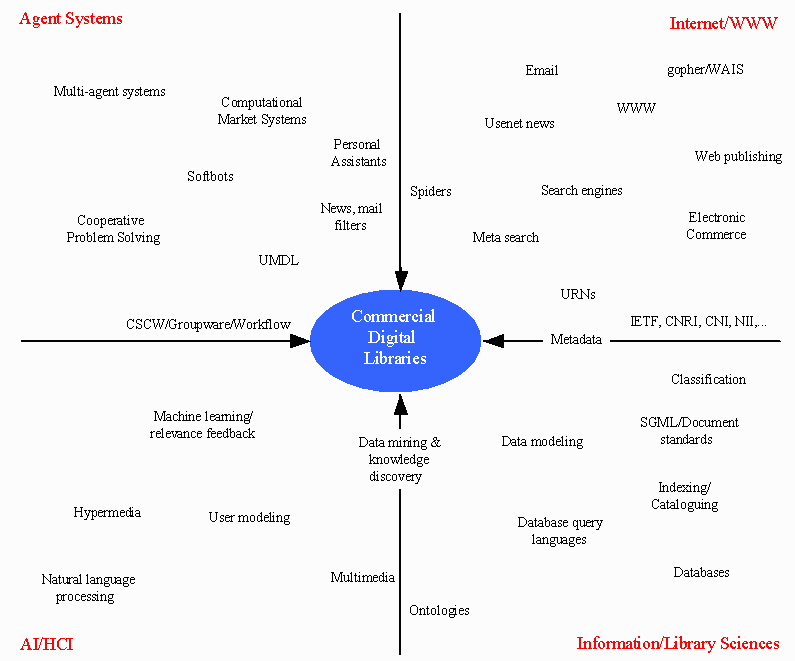 Figure 1: Technological developments
driving commercial digital libraries.
Figure 1: Technological developments
driving commercial digital libraries.
Developments in the information and library sciences have made large-scale, corporate databases common place, and make access to these databases easy by providing simple but powerful query languages (such as SQL). Document markup standards such as SGML, HTML, and MIME allow multi-media documents to be exchanged and manipulated by many different applications. Document summarizing, keyword extraction, indexing, and profiling allow users to understand the subject matter of a document without expending too much effort, and permit documents to be efficiently organized for subsequent retrieval.
It seems certain that the Internet will come to be seen as one of the most important developments in communications to occur in the 20th century, arguably more significant in its implications for commerce and industry than even the telephone or television. The prototypical Internet was first created nearly 30 years ago. Since then, its development has been marked by a steady increase in bandwidth, number of connected nodes, and of course processing power available to interpret and make use of the data transmitted across it. In tandem with this growth in infrastructure, there has been a steady increase in the richness of applications available to exploit it. From early email, FTP, and TELNET applications, frameworks like Usenet news, gopher, WAIS, and ultimately, the WWW have been developed, offering end-users ever-richer frameworks within which to communicate and collaborate. This development of both infrastructure and applications appears to have reached a commercial critical mass in the WWW today, which brings together a simple graphical user interface (making it usable by a mass market), multimedia content (making it useful for many home and industry applications), and a huge range of sites (so there is sufficient online content to make the WWW a truly useful tool for industry and commerce).
As we noted in the introduction, the "unadorned" WWW has a number of drawbacks that limit its effectiveness. From the earliest days of its development, the difficulty of finding and managing information on the WWW was apparent, and the first "meta-Web" applications were developed, in the form of search engines that aim to enable users to find information to meet their requirements (we are talking here of Lycos, Yahoo! and their many relatives). However, for all the reasons we discussed above, these developments were inherently limited. A considerable amount of effort is currently being devoted to building tools that overcome these limitations.
Note that although the basic transport mechanism for the WWW has existed for some time (ultimately, HTML pages are transmitted using TCP/IP), the WWW could not have been a success before the 1990s: there was neither the bandwidth to transmit multi-media content nor the processing power on client machines to interpret such content; and finally, the comparative sparseness of sites connected to the Internet would simply have made it uninteresting. It is only because all these separate components have come together in the 1990s that the WWW has become a compelling proposition.
Researchers in AI and HCI have developed a number of techniques that are enabling construction of personalized digital library products. Within AI, machine learning techniques are increasingly being applied to Internet problems. For example, Pattie Maes and colleagues at MIT Media Lab have pioneered the use of techniques that allow a program such as a mail reader, Usenet news reader, or WWW browser to learn about and represent the characteristic behavior of a user. This information can then be used in that user's interests, to act on their behalf pro-actively, without being explicitly instructed to do so. While it is not certain that the traditional WIMP direct manipulation paradigm for human computer interaction is in real decline, software that can take advantage of models of user behavior has obvious potential for dealing with the Internet. Other developments in HCI, (such as more powerful graphical environments, visualization tools, and multimedia), have made it possible to manipulate and navigate through types of media (such as video and audio) that until very recently were the domain of high powered dedicated workstations. Hypertext has become the dominant method for linking documents together, allowing users to explore information in highly dynamic, personal ways.
Agent-based computer systems have been the subject of academic research, primarily from AI [4] since about the late 1970s. Initially, researchers focused on distributed problem solving: essentially, how a problem could be effectively divided between groups of semi-autonomous problem solving components, such that they could each work on the problem independently, with the goal of ultimately integrating their results into a single whole [5]. Throughout the 1980s, research into multi-agent systems attracted an increasingly large amount of attention from researchers in AI, who began to recognize that the issues associated with societies of computational systems were, in fact, fundamental to most visions of the future of computing. Increasing attention was paid to multi-agent systems: systems built as a society of agents that could not be guaranteed to share any common goals or viewpoints. Issues such as negotiation and bargaining began to be investigated, with the goal of understanding how computers could be made to efficiently bargain for goods and services. With the rapid growth of the Internet throughout the 1990s, interest in agent technology has grown at a phenomenal rate. Issues such as bargaining and negotiation are seen to be of fundamental importance in making large scale electronic commerce a reality; simple autonomous agents that independently browse the WWW to find information on behalf of a user are an everyday reality; agents that filter news feeds and email are already passé; simple electronic markets, driven by agents, are beginning to attract attention; groupware/cooperative working tools are already in everyday use within industry; and agent standards are beginning to be considered seriously [6].
To summarize, we believe that the technology of commercial digital libraries will primarily be a synthesis of the four research areas outlined above:
We have described why we believe digital library technology is about to make a significant breakthrough into the commercial arena, and we have described the technological developments that make this breakthrough possible. We will now describe a commercial suite of products that brings together these disparate strands of research and development.
The Zuno Digital Library (ZunoDL) is a product suite framework that facilitates the development of domain-specific, agent-based information economies as the basis for deploying a range of sophisticated knowledge management applications. It facilitates the creation of Electronic Data Interchange (EDI) markets that support multiple publishers in vending (potentially any forms of) digital documents to customers, and provides customers with powerful tools for discovering, retrieving, filtering, analyzing, and managing such documents. ZunoDL consists of a distributed framework that is built as a collection of cooperating agents. Specifically, the framework covers three stakeholder or EDI market niches:
Consumers are end-users or librarians who, typically, will access the system through a standard Web browser or a Web-enabled client-side Java application. Producers are content owners who want to make their information resources available to these consumers. Facilitators are represented by the ZunoDL service network, which supports agents that map consumers to appropriate producers, and vice-versa. Depending on the particular application, the ZunoDL service network might reside consumer-side, producer-side, or a third, intermediate party (broker- or mediator-side) could even host it. Regardless of the physical distribution of the various agent types, communication between these three groups of agents takes place over the network: the Internet or an intranet, again, depending on the type of application.
Producer agents include two types: Library Service Agents (LSAs) and Catalogue Agents (CAs). LSAs reside at the publishers own sites and manage such services as repository access, document downloading, product billing, push-based advertising, site security, and publisher-side collaborative filtering, workgroup management, and workflow. CAs reside in the ZunoDL service network and represent the publishers who are registered with ZunoDL, caching summarized information and providing enhanced indexing services where appropriate.
User Interface Agents (UIAs) capture a consumer's actions and ongoing personal requirements for services such as searching (e.g. simple, enhanced, postdated, Query-By-Example, or even regularly repeated), user profiling, relevance feedback handling, document analysis (e.g. extracting key phrases, summaries, and other metadata elements), bookmarking, as well as a number of basic administration tasks such as adding new search resources. So, if the user is searching, for example, and this user for some reason is interrupted mid-session, the UIA is able to reinstate the unfinished search, notify the user when relevant new information becomes available, and/or conduct regular searches based on earlier stated requirements that had been captured by the UIA.
Search Agents (SAs) represent facilitators. SAs provide searching services, which they can enhance with components such as metadata and statistical term frequency indices, thesauri, and subject taxonomy trees in order to broaden, narrow, or refine searches that would otherwise be unsuccessful.
The roles of the various ZunoDL agents are best described through a typical usage scenario (see Figure 2). Users invoke ZunoDL through a standard Web browser or Web-enabled client-side application. On reaching the ZunoDL service network, the user will be allocated a user interface agent (UIA): their own if they have used the system before (topmost user in Figure 2), an "anonymous" one if they have not (bottom user in Figure 1). The user can then request a number of different services. The most common, a search, will involve the UIA requesting the services of one or more search agents (SAs). There may be a number of search agents in the system, with different capabilities. One may be slow but very thorough, for example. Another may optimize on getting some response at a low price. Another may be specialized in a given subject matter, a fourth might target speed of response.
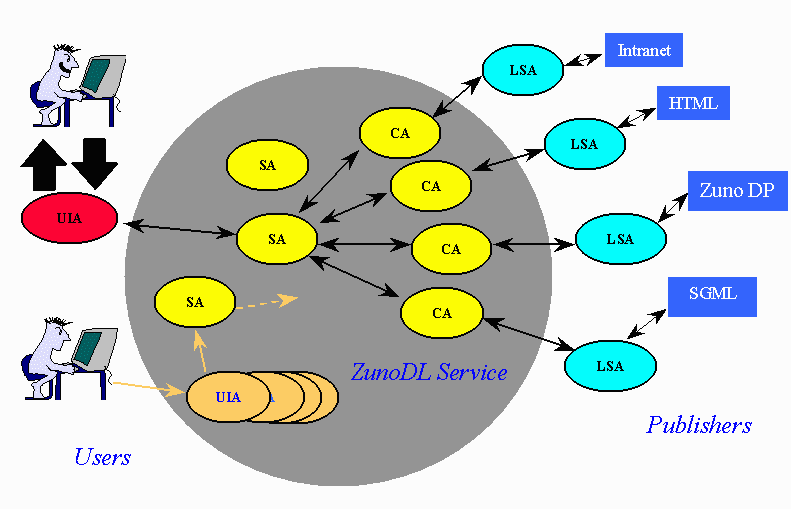 Figure 2: ZunoDL System
Framework.
Figure 2: ZunoDL System
Framework.
Whichever search type is employed, the selected search agent will ask a number of catalogue agents (CAs) for help. Each catalogue agent may use its local cached information repository to respond, or it will ask an appropriate library service agent (LSA) on the content owners site. The LSA has full access to the publishers information repository. Repositories, for example, may be structured as collections of HTML documents on a standard Web server; or they may be PDF or SGML files that are managed by a Web publishing tool such as ZDP (more on this below). The LSA responds through the CA and SA to the UIA, which then presents the search results to the user. If the user decides to download any of the identified documents, the purchase, if required, can be managed and the transactions completed between the UIA and appropriate LSA(s).
As mentioned above, the ZunoDL framework is designed as an information economy: specifically, a computational market of information and knowledge management agents that operate in a market-like manner [7,8,9]. We have argued elsewhere that economic markets provide a useful metaphor for the design and software engineering of complex distributed systems [10]. In particular, market-based systems are, by design, decentralized, capable of organizing themselves without central control, and capable of adapting themselves to changing supply and demand conditions. The market, or information economy, metaphor, therefore, seems highly appropriate for the digital library domain: producers and consumers of information interact in a market-like environment. Facilitators, which mediate interactions between consumers and producers and which, by design, can be given specific knowledge of the supply and demand for information products, can help increase the overall efficiency of the market.
We can illustrate the ZunoDL market mechanism using the example search scenario described above. From the start, each users UIA is designed to maximize the users long-term cumulative benefit from retrieving and purchasing information products or documents within the digital library. To achieve this, SAs are designed to compete to service the UIAs requests, where competition arises from the existence of different technologies and strategies that different SAs employ when searching for documents. After considering the bids put forward by the SAs, the UIA selects a given SA (typically just one) on the basis of the request or query profile (describing what the user is looking for) and a number of utility estimates, which measure how likely a given SA will return documents that are relevant to the query, based on the SAs past record at retrieving "similar" documents. Similarity is a factor that can be measured through a feature-based knowledge representation of documents called vector space modeling or VSM [11]. The selected SA will then attempt to find documents that maximize its anticipated reward (a positive or negative reinforcement signal from the user).
Once the SA has received documents from the appropriate CAs, the SA will pass the retrieved documents onto the UIA, which will be responsible for obtaining and propagating any user feedback concerning the worth or relevance of the presented documents. Specifically, such relevance feedback will be used both by the UIA to update its utility estimate of the chosen SA and by the SA itself to update its own strategy for discovering and retrieving future documents. Subsequent interactions between the user and the ZunoDL application will thus be influenced by, and benefit from, any earlier interactions.
The ZunoDL framework has, to date, been used to position two of Zuno's information and knowledge management products. The first of these is the Zuno Digital Publisher, or ZDP (see Figure 2). ZDP is a component-based suite of tools for producing, organizing, and publishing digital content online articles and documents in any format, video sequences, sound and other multimedia elements. The ZDP tool suite includes a collection of advanced user interface tools to enable browsing, searching, organizing, retrieving, linking, and annotating digital documents in high volume, high use environments (such as the WWW and corporate intranets). In addition, the suite includes a number of add-on components for handling billing, workflow, advertising, and demographic profiling. Although ZDP can integrate several of a publisher's physical repositories and make the content of these available to any number of Web-based users, it does so by centralizing the content onto a single server. In effect, then, ZDP acts as a multi-user, single (logical) repository digital library.
Zuno's second knowledge management product is a client-side User Interface Agent, or UIA. The UIA is the first of an integrated product suite aimed directly at businesses and individual online workers with a serious requirement for Internet/intranet knowledge management. As described above, the UIA is designed to capture the users actions and ongoing requirements for services such as searching, adaptive user profiling, relevance feedback handling, document analysis, as well as a number of basic administration tasks such as adding new search resources (e.g. Web-based search servers or engines, ZDP repositories, personal folders and mail boxes), bookmarking, and search performance logging.
TopWithin industry and commerce, there is an increasing demand for software tools to assist individuals and groups find, understand, manage, and organize information. This demand is widely expected to grow dramatically in the next century: ever more powerful tools will be required to help companies in maintaining a competitive edge. In this article, we have argued that digital library technology is likely to provide the main tool for building these systems. We have described what we see as the human and organizational imperatives that are driving the move towards the commercialization of digital library technology, and in particular we have identified what we perceive to be the main areas of technological development that make commercial digital libraries possible. These developments come primarily from AI, HCI, multi-agent systems, library and information sciences, and of course the Internet and WWW. Finally, we have described in outline a family of commercial digital library products, which are directed at meeting large-scale knowledge management requirements.
We would like to thank the other members of the Agents Systems Group at Zuno Ltd. for working with us to develop the ideas presented in the article. The views expressed in this article are those of the authors, and do not necessarily reflect those of Zuno Ltd.
Top|
Maes, P. (1994). Agents that reduce work and information overload. Communications of the ACM, 37(7):31-40, July. |
|
|
Dempsey, L. and Weibel, S.L. (1996). The Warwick metadata workshop: A framework for the deployment of resource description. D-Lib Magazine, July/August. Available as http://www.dlib.org/dlib/july96/07weibel.html. |
|
|
Lynch, C.; Michelson, A.; Preston, C.; and Summerhill, C.A. (1995). CNI white paper on networked information discovery and retrieval. Chapter One available as http://www.cni.org/projects/nidr/www/chapter-1.html. |
|
|
Wooldridge, M. and Jennings, N.R., editors. (1995). Intelligent Agents - Theories, Architectures and Languages. Lecture Notes on Artificial Intelligence, volume 890, Springer-Verlag: Berlin. |
|
|
Bond, A. and Gasser, L., editors. (1988). Readings in Distributed Artificial Intelligence. Morgan-Kaufmann Publishers: San Mateo, CA. |
|
|
The Agent Society Home Page. Available as http://www.agent.org/. |
|
|
Wellman, M.P. (1994). A computational market model for distributed configuration design. In Proceedings Conference of the American Association for Artificial Intelligence, pp. 401-407. |
|
|
Birmingham, W.P. (1995). An agent-based architecture for digital libraries. D-Lib Magazine, July. Available as http://www.dlib.org/dlib/July95/07birmingham.html. |
|
|
Ferguson, I.A. and Karakoulas, G.J. (1996). Multiagent learning and adaptation in an information filtering market. In Proceedings of the AAAI Spring Symposium on Adaptation, Coevolution and Learning in Multiagent Systems, Stanford University, CA. |
|
|
Ferguson, I.; Müller, J.; Pischel, M.; and Wooldridge, M. (1997). Robustness and scalability in digital libraries: A case for agent-based market systems. In Proc. IJCAI Workshop on AI and Digital Libraries, Nagoya, Japan, Aug. To appear. Available as http://www.dlib.com/people/innes/aiindl/papers/ferguson.ps. |
|
|
Salton, G. and McGill, M. (1983). Introduction to modern information retrieval. McGraw-Hill: New York, NY. |
© Copyright Zuno Ltd. 1997. All Rights Reserved. Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge.



hdl:cnri.dlib/june97-ferguson