|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Annelies van Nispen, Rutger Kramer and
René van Horik |
![]()
AbstractThis article reports on the X-past project carried out by the Netherlands Historical Data Archive (NHDA). The main goal of the project has been to investigate how the XML data format can improve the durability of and access to historical datasets. The X-past project furthermore investigated whether it would be possible to provide access to historical datasets by means of the "Open Archives Initiative—Protocol for Metadata Harvesting" (OAI-PMH). Within the framework of the X-past project a prototype information system has been developed and a number of users have been asked to report on usability issues concerning this system. IntroductionFor a number of decades historical data archives have been involved in the acquisition, documentation and dissemination of data sets created by historians and other scholars in the Humanities. Over the course of time, historical data archives gradually adapted their policies and activities in line with new insights and developments in ICT and research practices in the Humanities. The Netherlands Historical Data Archive (NHDA), a section active within the Netherlands Institute for Scientific Information Services (NIWI-KNAW) [1], coordinates the activities in the field of data archiving in the Humanities in the Netherlands. Its main data archiving strategy is based on the conversion of data sets into the common ASCII format and the creation of metadata based on international standards, such as the "Data Documentation Initiative" (DDI) [2]. In addition, the data-migration strategy is applied in order to avoid obsolescence of storage media and related hardware. The NHDA preserves and provides access to a heterogeneous collection of historical datasets created by historians for various research projects. Currently, a number of evolving technologies are influencing the way scholarly communication is carried out. The "extensible markup language" (XML) data format [3] is gaining ground as is the establishment of institutional repositories as part of a digital preservation strategy. The relevance of the standardized XML data format lies in its proclaimed non-proprietary, self-describing features. Storing digital objects as XML files has been recognized as a real possibility for both long-term storage and access to the data they represent [4]. Apart from migration of the files to more recent formats and emulation of extinct applications and operating systems, XML has been presented as a possible approach to prevent the files from becoming an uninterpretable clump. Institutional repositories enable transparent networked access to de-centralized collections of data objects. In a strict sense, open access to repositories does not improve the longevity of datasets, but it can act as a catalyst for addressing long-term archiving issues. Increasingly, institutes develop repositories as "Open Archives" for which commitment concerning long-term access is stated explicitly. The aim of this article is to report on theoretical and practical investigations, carried out by the NHDA, into the relevance of the XML data format and the "Open Archives" paradigm on the long-term preservation and dissemination of historical datasets. The research activities are carried out within the framework of the "eXtensible Past Project (also abbreviated as "X-past") [5]. The XML data format and digital archiving of historical data setsIn this section the current practice of the NHDA concerning the formatting of datasets is described, as well as the potential benefits of the XML data format as an alternative of the current practice. The NHDA has relied on platform-independent storage and migration as a strategy for long-term preservation. The format in which the data is archived must be reliable, retainable and, for the long distant future, human and computer readable. Since the founding of the NHDA in 1989 the ASCII data format has been used for the coding of archived datasets, because it is platform-independent and application-independent. Deposited datasets and variable lists are extracted from the current storage mode (currently, mostly Access and Excel) and are converted into ASCII (fixed format). An archived dataset deposited at the NHDA consists of a number of parts. Data archivists of the NHDA create the documentation, or metadata. The research data, mostly in tabular form, is accompanied by a variable list providing an overview of the labels of the columns in the datasets. Often, a codebook is available as well, which explains the codes used within the datasets. All parts mentioned above are stored in the archive. The datasets are made available online provided that the depositors of the datasets have given their permission to do this. Datasets and related data, such as variable lists and codebooks, are extracted from the deposited data format, (which are usually Access and Excel formats) and converted into the ASCII "fixed" data format. Applying the ASCII data format for the coding of datasets presents some problems. The rendering of the ASCII data format on different computer platforms and different applications such as word processors are subject to change over time. The correct interpretation of the ASCII data format requires additional background information, which is often "hidden" in the metadata. It seems that the ASCII data format is not explicit enough. Within the X-past project the relevance of the XML data format is being examined as an alternative for the current data archiving practice of the NHDA. The assumed benefit of the XML data format is that the interpretation and rendering of XML formatted data is clear both for humans and computers. The assumption is that an XML file can be archived and does not have to be converted later when a new generation of software is released. XML is a standard maintained by the influential World Wide Web Consortium (W3C), which guarantees development and maintenance of the standard. XML markup tags express the structure, content, and semantics of an XML formatted dataset. The syntax of these markup tags can be formalized and stored in a separate file, usually referred to as an XML Schema [6]. XML Schema is a language for restricting the structure of XML documents. The main advantage of the XML data format for long-term preservation is that it integrates data, metadata and structure. The Codebook/Variablelist and data can all be integrated in a single XML-file. Storage in an XML file is logical, and the data is stored per record including metadata that explains the meaning of the fields in a record. This is an advantage when it comes to historical data where the variable information is often important and the metadata is very descriptive. Figure 1 illustrates the way historical datasets currently are stored in the NHDA data archive using the ASCII data format. The data is based on the dataset "Merchants from the Southern Netherlands and the rise of Amsterdam staplemarket, 1578- 1630" [7]. Figure 1 contains a record of this dataset in ASCII format as well as a small part of the codebook that gives information on the meaning of the data in the dataset. Figure 2 contains the same information using the XML data format.
Figure 1. Record of "Merchants" dataset in ASCII fixed format representation and codebook. <record> <row> <persID> 26502 </persID> <family_name> Martensz </family_name> <first_name> Matheeus </first_name> <profession> Kruidenier </prefession> <origin> Antwerpen </origin> <date_of_entry> 19-05-1586 </date_of_entry> <entry_number> B </entry_number> <entry_page> 35 </entry_page> </row> </record> Figure 2. Record of "Merchants" dataset in XML data format. Figure 2 illustrates very well the advantage of the XML data format compared to the ASCII format that was shown in Figure 1. The "self-describing" XML data format has great potential for digital archiving because future users of the dataset will still be able to very easily evaluate the content and value of the dataset. Metadata for historical datasetsThis section covers the NHDA approach towards the creation and management of metadata of historical datasets and considers to what extent the XML data format can be used to improve the durability of the metadata. Metadata is important for the longevity of the documented datasets, because it enables the evaluation and retrieval of datasets in the future. Datasets with no metadata or with low quality metadata are under great risk of being forgotten. Data archivists at the NHDA compile metadata for datasets using data elements that are part of a metadata schema known as DDDI ("Dutch Data Documentation Initiative"). DDDI is a metadata schema that has been developed in cooperation with the Steinmetz Archive. This is the Dutch Social Science Data Archive, just as NHDA is part of NIWI. DDDI is a derivative of the standardized international metadata standard DDI, aimed at the description of datasets created in the Social Sciences. DDDI is compatible with the international DDI. The structure of the DDI standard is available in a very extensive XML Schema [8]. An information system has been developed for the entry and manipulation of metadata according to the DDDI format. This information system is an application based on the Oracle database management system. An export function of this system has been developed to map the data to the DDI standard. The DDDI metadata schema used by the NHDA deviates in a small but significant number of data elements from the standard DDI metadata schema. This fact motivated the X-past project to use a metadata registry as a tool to manage and apply the data elements required for the creation of metadata for historical datasets. A metadata registry contains various types of metadata elements. A registry provides term-level documentation of definitions and usage along with contextual annotations. It is possible to enter new metadata terms in the registry or re-use existing metadata terms [9]. The X-past project experimented with a metadata registry tool developed by the CORES project [10]. This CORES schema creation tool can export the data elements in the XML data format, according to the RDF Schema syntax [11]. RDF Schema is a specific XML Schema and contains vocabulary for describing the properties of RDF resources. RDF is a data model for objects and relations between them. With RDF the metadata elements relevant for historical datasets, historical sources, and other objects can be modeled, and RDF Schema provides the language to express properties and relations of objects. With the CORES schema creation tool a number of metadata elements from the DDDI schema were documented and exported in the XML data format according to the RDF Schema syntax. For a number of reasons, limited tests were carried out with the metadata registry tool. The registration of metadata elements in a metadata registry turned out to be very labor-intensive. Within the X-past project not enough resources were available to enter all DDDI data elements in the metadata registry. In addition, because the CORES project funding has ended, the X-past team was not certain whether the CORES metadata registry would continue to be available in the near future. Another reason for the limited attention on the metadata registry construct as a tool to apply the XML data format and to enable the long-term access to historical datasets, is the fact that the CORES schema tool uses the RDF Schema namespace. The preferred method for retrieval of historical datasets (which will be clarified below) requires that the metadata be expressed as an XML Schema, preferable using the Dublin Core data elements. Access to historical datasetsThis section describes how transparent and durable access to historical datasets can be achieved by applying an emerging communication protocol, and how the presentation of historical datasets can be improved by using style sheets. The XML data format is used to achieve both these aims, which are core components of a prototype information system developed under the framework of the X-past project. (This prototype will be described in the next section.) Transparent access to research data is one of the main tasks of a data archive. The "Open Archives Initiative Protocol for Metadata Harvesting" (OAI-PMH) [12] is a very promising protocol for creating an open archive that can act as a solution for durable access to datasets. The X-past project incorporated the OAI-PMH for the dissemination of metadata from a repository of historical datasets. A Data Provider as well as a Service Provider is implemented in order to enable web access to this metadata repository. The advantages of using this approach are:
In conclusion, the use of the OAI-PMH will make the implementation flexible, scalable, and easy to maintain and manage. Moreover, it will enable the NHDA to join future international initiatives for the interchange of research datasets. The flexibility of OAI-PMH will make decentralized and virtual data archiving possible. We think that decentralized data archiving will become an issue in the future. Thus, a virtual archive environment, or "collaboratory", can be created that provides easy access to different data collections at different locations, and that will improve the exchange of data and information among researchers. The rise of the OAI-PMH protocol can be attributed to its architecture, which is based on distributed storage, and its application of the XML data format. Traditional approaches for implementing interoperability between archives demanded that the archives involved had to decide on a uniform metadata standard and a centralized storage solution. Negotiations for reaching a consensus on these two issues more often than not took tremendous effort, as each archive had its own ideas on how to disseminate its collections. Moreover, the systems used by these archives often are incompatible with each other, making the enabling of communication between these systems a very complex problem. Another issue is more practical. Currently, the data of NHDA that can be downloaded through the Internet is presented in a simple ASCII format. User feedback proves that most clients find it difficult to study and re-use data presented in this format. Figure 3 contains an example of a format for historical datasets that is more appreciated by users. <?xml version="1.0" encoding="UTF-8"?><row> <VOYAGE> 252 </VOYAGE> <TIMES> 1 </TIMES> <CHAMBER> Amsterdam </CHAMBER> <BUILT> 1702 </BUILT> <SHIPTYPE> Spiegelschip </SHIPTYPE> <DEPART_D> 8 </DEPART_D> <DEPART_M> 10 </DEPART_M> <DEPART_Y> 1702 </DEPART_Y> <DEPART> 08 10 1702 </DEPART> </row> Figure 3: Record from the Dutch Asiatic Shipping dataset in XML representation Each field in the figure has an associated XML element. The CHAMBER element, for instance, contains information about the VOC chamber responsible for this particular voyage. The website disseminating this information will provide a context from which the user can deduce the meaning of this field; however, when confronted with just this XML record, it may not be clear to the user what the fields mean. To alleviate this problem, more information about the contents of this record can be provided in three ways by the X-past system.
The underlying XSLT code in this case would be:
<xsl:template match="CHAMBER">
<tr> <td><b>VOC Chamber responsible for Voyage</b></td> <td><xls:value-of select"."/></td> </tr> </xsl:template>
This way, the manager of the X-past system can reintroduce context to the records from a dataset at the time the record is rendered.
The XML data format and XSLT are both tools that were developed as part of the W3C effort for standardization of Internet technologies. The combination of these tools increases the accessibility of the dataset and makes the overall system more user-friendly. More research is required to experiment with the development of what could be described as electronic publication of data sets. User statistics prove that datasets that have been published as an electronic publication generate much more attention than other datasets. XSLT could be a valuable tool to provide for fast electronic publication of datasets. XML and Retrieval and Re-use of Historical DatasetsAn important goal of the X-past project is the retrieval of datasets. In the NHDA web catalogue it was possible to search and retrieve metadata, but it was impossible to search the research data itself. In order to achieve the goal of dataset retrieval and gain insight into the problems surrounding the XML storage of datasets, the project team decided to pick a number of test datasets present in the NHDA and employ them as use-cases for the development of the framework. The X-past system aims to make possible three things with regard to these datasets:
While some basic search and retrieval functionality has been developed, X-past is still working on better ways to improve accessibility of the datasets. Future developments will be based on user feedback gathered during the project. Re-use of research data is also a main objective of data archiving. Access to datasets must be guaranteed, and an important requirement is that it must be easy to download and import datasets into software packages, e,g., editors like Word or Wordpad, databases like Access, and spreadsheets like Excel. It seems that most software producers have now implemented XML in their software packages or plan to implement it in the near future. X-past experimented with importing XML files into Excel and Access, the two most commonly used software packages for the project. Importing XML files proved much easier than importing ASCII delimited files. The XML was recognized and converted very easily, quickly and flawlessly into tables. However, one disadvantage of downloading XML files is their size. Furthermore, we are uncertain which XML format will be best for the long term. The format we are currently using can be imported by some major office applications, but will that format still be usable with future applications? ProblemsThe applicability of the XML data format for different file types seems to be limited. If a researcher is interested in a specific publication, the researcher may be helped by an XML representation of the publication, since XML can be applied very straightforwardly to document-type files. XML is based on the use of characters, just like books and papers. But problems exist with files that are not represented solely by characters, such as image files and datasets. Images consist of pixels with a specific color code and require additional information, not directly tied to the visual aspects of the image, to be rendered correctly. Datasets contain characters, but they also may contain functionality, such as relational links between separate tables. One of the main advantages XML has over digitally oriented files—human readability and interpretability of the file—only applies to files with a document-like or tree-like structure and that contain nothing but characters. Although images and datasets can be represented by XML files, the XML representation will not be human readable. When XML needs to be applied to the storage of datasets, the problems become even more complex than they are for digital images. The actual data stored in the dataset will consist mostly of character-based fields, but images or complex file formats can also be stored in the dataset table. Moreover, dataset-dependant functionality such as stored procedures or reports are an integral part of the informational value of the dataset and should therefore be present in the long-term storage format. However, such functionality is normally represented by (scripting) program code and implicit programming environments, making it hard for archivists to capture the desired behaviour in a generic way. Although XML has proven itself as the format of choice for long-term storage of document-like objects such as articles or metadata, using XML for storage of datasets is not as obvious. As part of the X-past project, we decided to look into the usability of XML for long-term storage as well as for dissemination of the data itself. We applied XML only to the storage of data. Relational functionality is implemented as part of the dissemination framework. We intentionally left out the concerns of non-character data storage or complex features of datasets. Since the storage of these features is necessary to create a correct representation of the dataset, further research into this problem is necessary. The X-past prototypeIn the framework of the X-past project an information system was developed in order to gain experience with practical issues concerning the application of the XML data format for the archival storage and access of historical datasets. This section discusses the architecture of the X-past prototype system. The X-past system architecture has been developed as a modular system. The components of the system have separate functionality, and any of these components can easily be replaced by another component. This makes the whole system flexible and durable for the future.
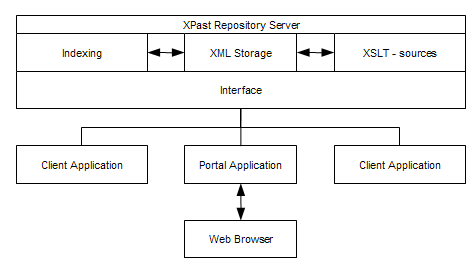
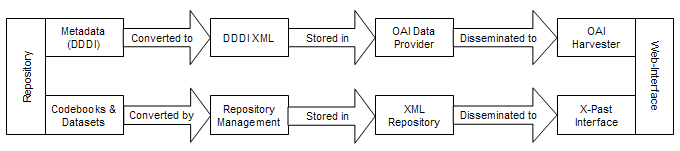
The X-past team decided to develop a central repository system where the datasets could be stored in XML format. The repository is responsible for providing access to the datasets, handling queries and requests for downloads, and providing display-templates for each record returned. A client system is able to connect to the repository, perform queries, and download result sets and data from the repository in XML format. Once downloaded, the XML can be transformed to any other format the client wishes by means of applying an XSL Template [13]. The Repository server consists of an indexing component, an XML Storage component and storage for XSL Template sources. In short, whenever a query comes in, the indexes are used to look up which records from which dataset should be returned. This yields a list of so called 'hits'. This hits list is used to retrieve the records from XML Storage. If applicable, the records can be accompanied by an XSL Template that defines how the record should be rendered in the target system. The Interface manages the communication between the repository server and several external clients. It is based on the HTTP protocol and uses either a GET or a POST method to transfer its parameters. Clients can use the interface to run queries, retrieve lists of records and retrieve individual records. The X-Past project developed a Portal application that serves as an intermediary between the user's web browser and the repository server. It translates the queries to the repository server and converts the records to HTML ready for rendering in a web browser. The X-past repository is linked to an OAI-PMH [14] repository that contains metadata about the datasets. A link defined in the metadata identifies the datasets and the tables that are part of a specific dataset. This makes it possible to run queries on all datasets, all tables in a dataset or a single dataset. The metadata can be harvested by any interested party anywhere in the world by applying the OAI protocol. This makes it possible for collections to be integrated virtually, i.e., access to multiple collections can be given from a single website or point of entry. The OAI-PMH setup effectively removes dependencies on system architecture and metadata compatibility. Archives opening their collections using OAI-PMH merely have to install a Data Provider module acting as a uniform access point to the metadata. The Data Provider is a passive software component connecting the metadata repository to the Internet by the use of XML and HTTP, and can be implemented to offer this access using multiple metadata formats such as Dublin Core or MARC. As soon as this Data Provider has been set up, it can be 'harvested'. This means that another system can connect to the Data Provider and download all of the metadata it needs in one of the available metadata formats. This downloaded metadata is stored and indexed by a Service Provider that will offer the actual end-user access to the metadata. One Service Provider can harvest as many collections as it sees fit and can offer access to all of these repositories at once, making it seem that the end-user is accessing one large collection. Information InterchangeIn a sense, the X-past system is a consumer of its own OAI repository. It harvests the metadata as well and links identifiers found in the metadata to the datasets X-past has in its repository. This means that the identifiers in the metadata of a dataset are the keys to accessing and examining the datasets in the repository. Any request for data at the address of the repository requires the identifier of the target dataset as a parameter. The information interchange (the combination of OAI and dataset dissemination) taking place in the X-Past system has been developed according to the following diagram:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
The metadata and the actual dataset data take two distinctive paths through the X-past system. The reason for this is that direct access to the catalogue with the metadata descriptions had to be offered to other interested parties. Anyone can harvest the metadata and use it to his or her own advantage. Transfer of the MetadataMetadata from the NHDA is being exported from data archive back office applications to DDDI XML format. The DDDI XML schema is compatible with the international (metadata) standard DDI. The DDDI XML records are being disseminated by an OAI Data Provider module. This module will offer the information about the datasets in the repository to interested parties. Transfer of the DatasetsThe codebooks contain variable information and, if applicable, an explanation of used codes. The structure, based on variable information, will be used to develop a schema. Because datasets are very heterogeneous in content and structure, it may be necessary to develop a different schema for each dataset. The datasets will be exported to XML in the format specified by these schemas. Only datasets with text-based fields (e.g., in databases, including memo fields and numerical fields) were transferred. Datasets containing images or bit streams were not selected. The XML Data and Schemas will be managed by the Repository Manager. This module will take care of indexing the XML data in order to perform full text queries on it. When adding new datasets into the repository, or when changes need to be performed on the XML datasets, the Repository Manager will be needed to re-index the datasets. The Repository Manager also keeps track of which datasets are available, and what their associated XML Schema is. It will function as an access point for the Repository Interface. One of two approaches can be used to convert the data of a dataset to XML data structure:
The former will yield one large XML file and will have a certain amount of relational consistency with the original dataset (linked records can be embedded within each other). The latter will result in several XML files that are easier to handle, but that lose all of the relational information present in the dataset. In this case, the relational information must be captured in a separate file using either XML-specific linking techniques, such as XLink [15], or a self-defined mechanism for coupling the tables. X-past chose to convert the tables to individual files. In order to conserve the relational information, the system that will store, manage and disseminate the datasets will have a so-called 'registry-file' containing relational information for each table in the dataset. The way the tables are converted into XML differs between datasets. Specialized parsers had to be developed for different datasets and codebooks. This means a highly specialized and labor-intensive approach turned out to be necessary, but only for the first conversion. Other datasets with more or less the same format can be parsed by the software that was developed for the first conversion. What has become clear from converting these different datasets is that each dataset format requires its own approach. To alleviate this, an intermediate format can be chosen to which the majority of applications still in use can export, such as character-separated files, and define a parser for this format. Formats used by applications that do not support character-separated files or that are no longer able to run on current platforms will need their own special parser. One major problem of the conversion of datasets to XML is the loss of functionality. Special features like relationships, stored procedures, user management and dataset reports are left behind in the dataset when a conversion of the data to XML is performed. Some of these features, although they represent a part of the semantics of the dataset, are not of great importance to the future use of it. Others, most notably relationships between tables, must be preserved in order to correctly reuse the dataset later on. Relationships between tables were implemented in the X-past system to make it possible to recreate these relationships in future. When uploading the dataset, specifications of dataset tables, relations and fields have to be defined. Whenever a query is performed on one table in the dataset, the relational tables are also queried for records related to result records. ConclusionsThe work of the X-past project is far from complete. The system we have implemented shows a glimpse of how datasets can be preserved for longer time spans and at the same time be disseminated. This is fine for demonstration purposes, but it is not quite ready to be seen as a proof-of-concept. In order to determine whether XML can be of use for the long-term preservation of datasets, additional development and research needs to take place. For instance, the way in which relational information is currently registered in the system is not tied to the actual XML. This means that relational information will not be apparent when a single XML record is investigated. There is a standard way of providing relational information based on and embedded in XML: XLink. XLink allows for (parts of) XML documents to be linked to each other on a record-by-record basis. We need to look into the applicability and usefulness of XLink for providing relational information and embedding this specific dataset functionality into the XML. As for the applicability of XML for long-term storage, our conclusions are not yet definitive. However, from what we have seen by implementing the system, simply converting the dataset to XML will not be sufficient—not even when ample documentation is provided on how to regenerate the dataset and some specific functionality. If XML is to be used for long-term storage of datasets, it should be applied within the framework of a larger solution. XML can be used for the data, but the actual dataset should be represented by something 'larger'. Functionality that is implicitly included within complex datasets should be captured in a generic implementation in the framework in order to make an optimal semantic mapping between an original dataset and an archived dataset possible. Long-term preservation of binary information is another major problem we're facing when storing datasets. The general question will be how to store the data in a way that will allow us to interpret the information many years from now. For now, storing the bit stream in a text-encoded form such as Base64 and accompanying it with metadata seems to be the best option. The metadata would have to describe what kind of file or object is represented by the bit stream, indicate which kind of text encoding is used, indicate which program is needed to open it, contain a reference to documentation about the format (if possible), and contain a datestamp. The X-past prototype was reviewed by a specified user group and another international group that responded to X-past's call for reviews through digital preservation mailing lists. The prototype has been adjusted on:
A lot of work remains to be done, and X-past hopes to do a follow-up project to look more deeply into matters that have only been touched upon now. The X-past team would be very grateful for all comments and remarks. The prototype can be visited at: <http://www.niwi.knaw.nl/nl/geschiedenis/projecten/xpast_copy1/>. Please contact us at the following e-mail address: <Xpast@niwi.knaw.nl>. Notes and References1 More information can be found at: <http://www.niwi.knaw.nl/en/geschiedenis>. 2 More information on the DDI can be found at: <http://www.icpsr.umich.edu/DDI>. 3 See <http://www.w3c.org/XML>. 4 For more about using XML files for long-term storage and access, see:
5 The X-past project was financed by a grant of the Royal Netherlands Academy of Arts and Sciences. 6 See <http://www.w3.org/XML/Schema>. 7 More information on this dataset can be found at: <http://www.niwi.knaw.nl/en/geschiedenis/collecties/catalogue/all_studies/15081/>. 8 The XML Schema of the DDI can be found at: <http://www.icpsr.umich.edu/DDI/users/dtd/index.html>. 9 For more background information on Metadata Registries and other related concepts see the Glossary of the CORES project: <http://www.cores-eu.net/glossary/>. 10 The registry of the CORES project can be found at: <http://cores.dsd.sztaki.hu/>. Also a schema creation tool is available, see: <http://sourceforge.net/projects/schemas/>. 11 Information on RDF can be found at: <http://www.w3c.org/RDF/>. 12 The OAI-PMH is described at: <http://www.openarchives.org/OAI/openarchivesprotocol.html>. 13 XSL Working Group, "The Extensible Stylesheet Language Family", W3C Architecture Domain, <http://www.w3.org/Style/XSL/>. 14 Open Archives Initiative, <http://www.openarchives.org/>. 15 "XML Linking Language (XLink) Version 1.0", W3C Recommendation 27 June 2001, <http://www.w3.org/TR/2001/REC-xlink-20010627/>.Copyright © 2005 Annelies van Nispen, Rutger Kramer and René van Hork |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/february2005-vannispen
|