| ||
D-Lib Magazine | |
| Marilyn McClelland Gary Geisler |
![]()
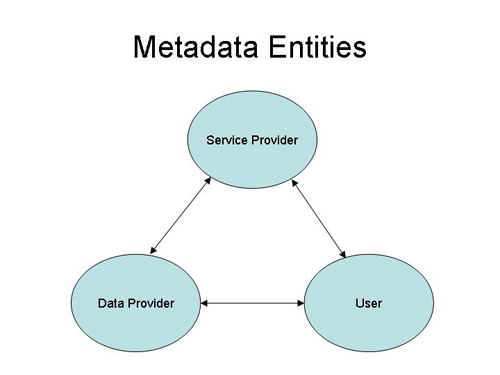
AbstractMuch of the usefulness of digital libraries lies in their ability to provide services for data from distributed repositories, and many research projects are investigating frameworks for interoperability. In this paper, we report on the experiences and lessons learned by iLumina after importing IMS metadata. iLumina utilizes the IMS metadata specification, which allows for a rich set of metadata (Dublin Core has a simpler metadata scheme that can be mapped onto a subset of the IMS metadata). Our experiences identify questions regarding intellectual property rights for metadata, protocols for enriched metadata, and tips for designing metadata services. IntroductionMuch work has been done in the digital library community to facilitate the exchange of metadata between digital libraries. Specifications like Dublin Core, IEEE Learning Object Metadata (LOM), or IMS [1] have been developed for tagging metadata in a standard xml format [IMS Specification]. Frameworks are being developed to provide interoperability for digital libraries [Arms, Fulker, IMS Model, and Lagoze] with many using the protocol for metadata harvesting developed by the Open Archives Initiative (OAI) [Van de Sompel, Warner]. For the discussion here, we consider a simple, high-level view of the interaction of metadata entities, shown in Figure 1, which illustrates the logical separation of data providers and service providers to distinguish the different roles in handling metadata [Van de Sompel, Warner]. Our digital library project, iLumina (http://www.ilumina-dlib.org), is both a data provider and a service provider. Prior to the winter of 2002, iLumina consisted only of metadata that had been created by iLumina contributors. During the winter of 2002, iLumina imported metadata from another data provider. In this article we discuss challenges that arose as we worked to integrate iLumina services with imported metadata.
We also discuss here the obstacles and challenges we did not adequately anticipate that relate primarily to the integration of the imported data into the services provided by iLumina. Our goal for this article is to discuss the 'lessons learned' that identify relevant considerations for a better design of the repository as well as services that could generalize to other implementers. Some of these challenges, such as the use of different vocabularies, have been discussed elsewhere; but this paper reports on specific, tangible experiences. In some cases, we can suggest alternative solutions. In other cases, the import experience identifies unanswered questions that need to be addressed by the digital library community. Perhaps sharing our experiences can provide a guide to the hazards that need to be considered in the design of repository persistence and digital library services. We start with an overview of the iLumina project to provide a context for our import experiences. Next we share the issues and challenges we encountered and the unanswered questions we identified. Finally, we discuss some of the lessons we learned that will help shape the redesign of our repository and services. Brief Overview of iLuminaiLumina is a digital library of undergraduate teaching materials for science, mathematics, technology and engineering (SMETE) education, now being developed by Eduprise, the University of North Carolina at Wilmington (UNCW), Georgia State University, Grand Valley State, and Virginia Tech [2]. Our experience suggests that faculty across the country have created a wealth of digital resources for teaching, often small or granular in size, and are willing to share them. However, faculty lack a repository where they can submit their materials, find related ones, create new content, and collectively improve both the quantity and quality of digital teaching resources. iLumina will provide such a repository, and related community and user services. To promote such sharing, iLumina not only provides services to facilitate the creation and acquisition of resources, but also offers tools to end-users that will enable them to find and make use of digital objects. One related theme is that IMS metadata can underpin tools that enable resource sharing. iLumina uses IMS metadata tools to create rich and standardized descriptions of the learning objects that it manages. However, for this to work effectively, the costs of creating such rich metadata must be (relatively) low in comparison to its benefits. Many have argued that minimalist metadata (such as DC Core), is not only easier to create than IMS/IEEE descriptions, but also more cost-effective. One question the iLumina project is addressing is whether this is true. Architecturally, iLumina is both distributed (content) and centralized (metadata). That is, we encourage content providers to maintain their own materials, but we gather and manage their metadata so end-users can come to a single site — the iLumina portal — to find these distributed collections. iLumina implements the full IMS metadata information model (including recent updates) and maintains the data through relational mappings into an SQL Server. Building on this model, we have developed a set of tools to create, manage, search and view IMS metadata and the iLumina resources they describe. This has enabled us to catalog numerous library resources (currently, over 800 and increasing steadily). Many of these resources are actually collections embedded in the larger iLumina collection, and we provide tools to describe and view (with metadata) not only individual resources, but the special collections themselves. IMS metadata provides a foundation for a number of core library services already in place, including basic (and advanced) search, browsing, and a contribution form allowing new content providers to catalog their materials for iLumina (although materials are reviewed before being finally admitted to the library). We have also moved ahead on an extended set of services, such as personal collections [Geisler] and ratings, although most of these are still in the development stage. Maintaining profile or identity data for users is one of the services iLumina provides to simplify contributions. A registered user of the iLumina site can create and edit a profile of personal information. When the user logs on and chooses to make a contribution, this profile information is used to automatically populate the contributor's fields in the metadata specification. Thus, users do not have to reenter their personal information for each contribution. iLumina acquires metadata both by cataloging metadata from individuals and by importing metadata in batches. While importing yields high amounts of metadata, those processes do not invite users to participate in the library environment. Therefore, a web-based Contribution Form was designed for registered users to play an active role in contributing a resource and its metadata into iLumina. To minimize cataloging errors, we collect metadata using a combination of drop-down lists containing controlled vocabularies and fill-in-the-blank fields. One of the challenges of acquiring metadata is to minimize the cost of metadata creation for authors. Some solutions we have implemented to contain these costs include:
Before contributions to iLumina are exposed publicly through iLumina tools, each contribution is assigned to an appropriate Area Editor, based on the discipline of the resource. The Area Editor decides whether to accept or reject the contribution. Only resources that have been accepted will be publicly available through the iLumina portal and services. Undergraduate math and science students are hired and trained as catalogers for iLumina. After a minimal amount of training, these students have proven to be effective catalogers. In some cases, student catalogers fill out the iLumina contribution form for the resource author. In other cases, authors fill in a minimal amount of metadata and student catalogers complete the remaining metadata. Student catalogers also clean up metadata by using the iLumina browse tools to pinpoint anomalies in the data. The Import ExperienceUnder the Open Archives Initiative (OAI), numerous repositories provide a standard protocol for harvesting their metadata. Metadata can be harvested in a variety of standard formats like Dublin Core (the required OAI format) or IMS. Since iLumina was developed to support the IMS standard, we wanted to import metadata in the IMS format. Though we realize that Dublin Core can be mapped to IMS, Dublin Core is a subset of IMS, so our thought was that resources cataloged using IMS might have richer metadata. Thus we selected an OAI data provider that exports in IMS format. After importing metadata from an OAI data provider and working with the metadata for integrations with iLumina services, we realized that opportunities exist to enrich, or add value to the metadata. The metadata can be enriched by:
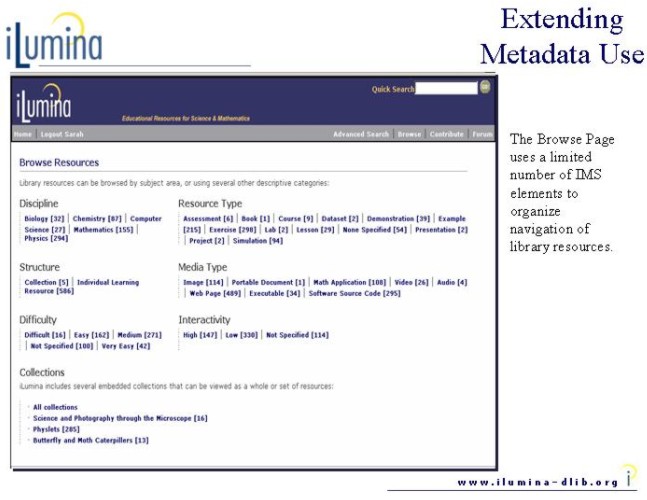
One of the services provided by iLumina is a browse facility that provides a profile of the learning resources (as shown in Figure 2). Thus, some of the functionality of the iLumina site is built on the expectation that data will be present in certain fields to drive the browse functionality. For example, the browse page provides views of the metadata based on media type and learning resource type. The media type is developed from mapping the data type (essentially a mime type) in /lom/technical/format [3]. In the data we imported into iLumina, however, neither the /lom/technical/format or /lom/educational/learningresourcetype are populated, so the imported data is not visible in these browser views of the metadata. This is not an error (since learning resource type is not a required IMS metadata element), but it highlights differences in the cataloging of metadata and the risks of building site (browse) functionality based on the expectation that specific (non-mandatory) elements would have value in imported metadata records.
To some extent, the problems that arise from missing elements in imported metadata — or from elements in imported metadata whose values are from different vocabularies used in the importing digital library environment — might be solved if catalogers were free to modify or enrich imported metadata by adding values for unpopulated elements. The problem is the lack of clarity about the conventions and/or courtesies surrounding the use of, and freedom to change, the shared metadata [Bird]. iLumina discussed intellectual property rights early on and developed separate rights statements for our resources and our metadata. Our perception was that the rights statements within the IMS specification pertain to the rights of the learning resource and not the metadata. Basically, our metadata rights statement gives users permission to copy and redistribute for non-commercial use. After working through importing metadata and integrating it with our services, we uncovered additional issues related to the intellectual property rights of the metadata, as indicated by the opportunities to enrich metadata listed above. Another import problem occurred when the field size of an imported element exceeded the field size in the database. For example, IMS suggests that at minimum a field size up to 2000 characters should be supported for /lom/general/description. In our database, description has a field size of 8000 characters. However, one of the imported items had a description larger than 8000 characters. To support a field size larger than 8000 characters, we would have to switch to using a different datatype in the database and retest all the interfaces to the database. Even if we redesign the database to accommodate this particular metadata item, this is an arbitrary method to determine the field size to support. Our options are to reject the metadata instance if any field size is exceeded or truncate fields to fit our database knowing that we will not be able to roundtrip the xml instance. Neither of these current options is very appealing. Questions relating to the metadata intellectual property rights that we did not resolve include:
Currently, in IMS, IEEE LOM and OAI there is no a specified policy for editing or exporting metadata that was imported from another repository. As a starting point, iLumina can make individual agreements with other repositories that specify under what circumstances iLumina can make changes to the metadata and whether or not iLumina can export the revised metadata. iLumina should be able to roundtrip the original metadata and provide it for export on request. For enriched metadata, iLumina's modification of the metadata could be reflected only in a vague way, via the IMS specification, by adding a meta-metadata entry for validation with a 'known' iLumina entity (LOM Jan18-02 mandates only one creator, so this would eliminate the option of two creators). There is no mechanism that would track specific modifications. For example, if iLumina fleshed out the metadata by adding previously unpopulated tags or correcting errors after validating values, the meta-metadata entry would only indicate iLumina as the metadata contributor as well as provide a date. There would be no details on the specific modifications. On the browse page, the imported data is revealed under the discipline element. The problem here is not that the imported data omits the discipline element, but rather that it often uses a discipline classification scheme different from that used by iLumina. More generally, the imported metadata had several elements that used different vocabularies from iLumina. Therefore, even though the other repository also uses a controlled vocabulary, since it is a different vocabulary, the metadata does not fully exploit the services provided by iLumina. This is not a problem unique to iLumina and the libraries from which we have imported materials. Currently, although many OAI data providers use controlled vocabularies, there is little standardization on which controlled vocabulary is used [Liu]. This situation complicates the ability of the service provider to develop generic services for data generated by a variety of providers. In light of diverse controlled vocabularies, in the next stage of iLumina development more care will be taken to develop a flexible architecture. To recap, as a result of our experience importing metadata to iLumina, the following issues have been identified:
Lessons LearnedMetadata will be incomplete and contain errors.
Specialized vocabularies complicate importing data.
Metadata specifications are evolving.
ConclusionsWe have discussed iLumina and the obstacles we encountered when importing metadata into our library. We are less naïve after the import experience. We have gathered ideas to use in the next rewrite of iLumina to build a more effective system. Some of our challenges are likely due to our relative inexperience in the implementation of IMS metadata and the transacting of metadata across repositories. However, many of the difficulties we face, such as the evolving processes for handling intellectual property rights, are common to everyone in the digital library community. Indeed, these problems are likely to become even more acute in the immediate future, as a growing community of distributed content, metadata and service providers begins to adopt the OAI metadata harvesting protocol. The National Science, Technology, Engineering and Mathematics Digital Library (NSDL) is a case in point [Saulnier, Zia]. Scheduled for debut in the fall of 2002, the NSDL hopes to become, over the next five years, the largest library of digital teaching and learning materials in the nation. The National Science Foundation (NSF), through its Division of Undergraduate Education is funding the initial development of the NSDL, providing support to over 60 coordinated projects (including iLumina) that will contribute collections and services. Because the NSDL is a massively distributed project, common metadata standards and processes for transacting and reusing these descriptions will be essential to knit together the diverse pieces. An initial set of standards for NSDL has been established, and working groups in this area are already tackling some of the hard problems that remain. This article outlines some of those challenges and underscores the point that not all the problems will be solved merely by adopting a common metadata element schema. Notes1. IMS originally was the acronym for Instructional Management System. The organization retained the IMS initials and adopted the name IMS Global Learning Consortium, Inc. The consortium involves industry, academic, and government communities in the design and use of open specifications to provide interoperability for distributed learning services and technologies. In addition to learning resource metadata specifications, IMS has specifications in a number of other areas. For more information on IMS specifications, see the IMS website at <http://www.imsproject.org>. 2. This work is funded as part of the NSF DLI-Phase 2, grant #0002935. For details on the project see the iLumina website at <http://www.ilumina-dlib.org>. 3. This is the standard xpath syntax for hierarchical IMS/IEEE LOM metadata elements. In the case of /lom/technical/format, for example, the xml root element is "lom" with a child metadata element "technical". The metadata element "technical" has a child metadata element with the name "format"; other children of "lom" include educational, general, and relation. References[Arms] Arms, W. Y., D. Hillmann, C. Lagoze, D. Krafft, R. Marisa, J. Saylor, C. Terrizzi, and H. Van de Sompel, "A Spectrum of Interoperability: The Site for Science Prototype for the NSDL". D-Lib Magazine, 8(1), January 2002, <http://www.dlib.org/dlib/january02/arms/01arms.html>. [Bird] Bird, S., "White Paper on Machine-Readable Rights Information". Prepared for the Technical Committee of the Open Archives Initiative, October 2001, <http://www.ldc.upenn.edu/sb/oai/rights.html>. [Fulker] Fulker, D, and G. Janee, "Components of an NSDL Architecture: Technical Scope and Functional Model". Submitted to the Joint Conference on Digital Libraries, Portland, 2002. [Geisler] Geisler, G, S. Giersch, D. McArthur, and M. McClelland, "Creating Virtual Collections in Digital Libraries: Benefits and Implementation Issues". Accepted as a long paper for the Joint Conference on Digital Libraries, Portland, 2002. [IMS Model] "IMS Digital Repositories Interoperability Information Model", version 1.0 Base Specification, February 5, 2002, <http://www.imsproject.org/digitalrepositoriesteam.html>. [IMS Specification] "IMS Learning Resource Meta-data Specification", <http://www.imsproject.org/metadata/index.html>. [Lagoze] Lagoze, C. (ed) "Core Services in the Architecture of the National Digital Library for Science Education (NSDL)". Submitted to the Joint Conference on Digital Libraries, Portland, 2002. [Liu] Liu, X., K. Maly, M. Zubair, and M. Nelson, "Arc - An OAI Service Provider for Digital Library Federation", D-Lib Magazine,, 7(4) April 2001, <http://www.dlib.org/dlib/april01/liu/04liu.html>. [NSDL} NSDL: Functional Requirements Draft - working version 1.0 as of January 13, 2002. <http://repository.comm.nsdlib.org/cgi-bin/wiki.pl?FunctionalRequirementsDraft>. [Saulnier] Saulnier, B., "NSDL Portal Power," Cornell Engineering Magazine, 7(3), Fall 2001, <http://nsdl.comm.nsdlib.org/portalpower.html>. [Van de Sompel] Van de Sompel, H. and C. Lagoze, "The Open Archives Initiative Protocol for Metadata Harvesting", 2001, <http://www.openarchives.org/OAI/openarchivesprotocol.html>. [Warner] Warner, S. "Exposing and Harvesting Metadata Using the OAI Metadata Harvesting Protocol: A Tutorial". HEP Libraries Webzine, Issue 4, June 2001. <http://library.cern.ch/HEPLW/4/papers/3/>. [Zia] Zia, L., "Growing a National Learning Environments and Resources Network for Science, Mathematics, Engineering and Technology Education," D-Lib Magazine, 7(3), 2001, <http://www.dlib.org/dlib/march01/zia/03zia.html>. Copyright 2002 © Marilyn McClelland, David McArthur, Sarah Giersch, and Gary Geisler | |
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2002-mcclelland
|